
Multivariate Time Series Forecasting: VAR and VECM Models Explained
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.

A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
A practical introduction to building ARIMA models in Python for reliable time series forecasting.
Learn specialized feature engineering techniques to make time series data more predictive for machine learning models.
Discover the essential steps of Exploratory Data Analysis (EDA) and how to gain insights from your data before building models.
Least Angle Regression, or LARS, is an efficient regression algorithm designed for high-dimensional data. It provides a pathwise approach to linear regression that is especially useful in the presence of multicollinearity or when feature selection is crucial.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Explore time-series classification in Python with step-by-step examples using simple models, the catch22 feature set, and UEA/UCR repository benchmarking with statistical tests.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
Explore Automated Prompt Engineering (APE), a powerful method to automate and optimize prompts for Large Language Models, enhancing their task performance and efficiency.
Explore how to perform effective Exploratory Data Analysis (EDA) using Pandas, a powerful Python library. Learn data loading, cleaning, visualization, and advanced EDA techniques.
Monotonic constraints are crucial for building reliable and interpretable machine learning models. Discover how they are applied in causal ML and business decisions.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
A deep dive into using Genetic Algorithms to create more accurate, interpretable decision trees for classification tasks.
COPOD is a popular anomaly detection model, but how well does it perform in practice? This article discusses critical validation issues in third-party models and lessons learned from COPOD.
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
Feature engineering is crucial in machine learning, but it’s easy to make mistakes that lead to inaccurate models. This article highlights five common pitfalls and provides strategies to avoid them.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Explore how Python and machine learning can be applied to analyze and improve building energy efficiency. Learn key techniques for assessing sustainability, optimizing energy usage, and reducing carbon footprints.
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
Learn how to design and implement utility classes in Python. This guide covers best practices, real-world examples, and tips for building reusable, efficient code using object-oriented programming.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
Imagine building a model to predict house prices based on features like size, location, and amenities. If you accidentally include the actual selling price during training, the model learns this private information instead of the underlying patterns in the other features. This is data leakage, co...
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
Introducing ikNN: An Interpretable k Nearest Neighbors Model
Sequential detection of structural changes in models is a critical aspect in various domains, enabling timely and informed decision-making. This involves identifying moments when the parameters or structure of a model change, often signaling significant events or shifts in the underlying data-gen...
Outlier detection is a critical task in machine learning, particularly within unsupervised learning, where data labels are absent. The goal is to identify items in a dataset that deviate significantly from the norm. This technique is essential across numerous domains, including fraud detection, s...
Outlier detection presents significant challenges, particularly in evaluating the effectiveness of outlier detection algorithms. Traditional methods of evaluation, such as those used in predictive modeling, are often inapplicable due to the lack of labeled data. This article introduces a method k...
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
1. Introduction
Basics of the Logrank Test
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Absorption and Reflection
Introduction
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Stepwise Regression
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Discover critical lessons learned from validating COPOD, a popular anomaly detection model, through test-driven validation techniques. Avoid common pitfalls in anomaly detection modeling.
Exploring Climate Value at Risk (VaR) from a data science perspective, detailing its role in assessing financial risks associated with climate change.
Sequential change-point detection plays a crucial role in real-time monitoring across industries. Learn about advanced methods, their practical applications, and how they help detect changes in univariate models.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
A comprehensive comparison of Value at Risk (VaR) and Expected Shortfall (ES) in financial risk management, with a focus on their performance during volatile and stable market conditions.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
Explore the diverse applications of rolling windows in signal processing, covering both the underlying theory and practical implementations.
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Dive into Gaussian Processes for time-series analysis using Python, combining flexible modeling with Bayesian inference for trends, seasonality, and noise.
A detailed exploration of Customer Lifetime Value (CLV) for data practitioners and marketers, including its calculation, prediction, and integration with other business data.
Explore the key concepts of Mean Time Between Failures (MTBF), how it is calculated, its applications, and its alternatives in system reliability.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
Learn about Principal Component Analysis (PCA) and how it helps in feature extraction, dimensionality reduction, and identifying key patterns in data.
Delve into bootstrapping, a versatile statistical technique for estimating the sampling distribution of a statistic, offering insights into its applications and implementation.
Learn how time series decomposition reveals trend, seasonality, and residual components for clearer forecasting insights.
Explore Bayesian A/B testing as a powerful framework for analyzing conversion rates, providing more nuanced insights than traditional frequentist approaches.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
This article explores the use of K-means clustering in crime analysis, including practical implementation, case studies, and future directions.
A step-by-step guide to implementing Linear Regression from scratch using the Normal Equation method, complete with Python code and evaluation techniques.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
Explore the architecture of ordinal regression models, their applications in real-world data, and how marginal effects enhance the interpretability of complex models using Python.
Leveraging customer behavior through predictive modeling, the BG/NBD model offers a more accurate approach to demand forecasting in the supply chain compared to traditional time-series models.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Learn the fundamentals of ARIMA modeling for time series analysis. This guide covers the AR, I, and MA components, model identification, validation, and its comparison with other models.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
This article delves into the Chi-Square test, a fundamental tool for analyzing categorical data, with a focus on its applications in goodness-of-fit and tests of independence.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
SMOTE generates synthetic samples to rebalance datasets, but using it blindly can create unrealistic data and biased models.
Ethical considerations are critical when deploying machine learning systems that affect real people.
Hyperparameter tuning can drastically improve model performance. Explore common search strategies and tools.
Neural networks power many modern AI applications. This article introduces their basic structure and training process.
Learn specialized feature engineering techniques to make time series data more predictive for machine learning models.
Mastering mathematics and statistics is essential for understanding data science algorithms and avoiding common pitfalls when building models.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Machine learning is revolutionizing fall prevention in elderly care by predicting the likelihood of falls through wearable sensor data, mobility analysis, and health history insights.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Predictive analytics in healthcare is transforming how providers foresee health problems using machine learning and patient data. This article discusses key use cases such as hospital readmissions and chronic disease management.
Machine learning is revolutionizing medical diagnosis by providing faster, more accurate tools for detecting diseases such as cancer, heart disease, and neurological disorders.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
Feature engineering is crucial in machine learning, but it’s easy to make mistakes that lead to inaccurate models. This article highlights five common pitfalls and provides strategies to avoid them.
Machine learning is revolutionizing forest fire management through advanced models, real-time data integration, and emerging technologies like IoT and blockchain, offering a holistic and adaptive strategy for combating forest fires.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
Learn how machine learning optimizes supply chain operations by enhancing demand forecasting, inventory management, logistics, and more, driving efficiency and business value.
An exploration of cross-validation techniques in machine learning, focusing on methods to evaluate and enhance model performance while mitigating overfitting risks.
Explore how Python and machine learning can be applied to analyze and improve building energy efficiency. Learn key techniques for assessing sustainability, optimizing energy usage, and reducing carbon footprints.
Learn why a deep understanding of machine learning fundamentals is more valuable than expertise in specific tools and frameworks.
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
1. Introduction
Introduction
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Introduction
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Introduction
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
This article delves into the core mathematical principles behind machine learning, including classification and regression settings, loss functions, risk minimization, decision trees, and more.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Delve into the fears and complexities of artificial intelligence and automation, addressing concerns like job displacement, data privacy, ethical decision-making, and the true capabilities and limitations of AI.
A deep dive into the ethical challenges of data science, covering privacy, bias, social impact, and the need for responsible AI decision-making.
Discover how data science, a multidisciplinary field combining statistics, computer science, and domain expertise, can drive better business decisions and outcomes.
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Learn how to design robust data preprocessing pipelines that prepare raw data for modeling.
This article explores the use of K-means clustering in crime analysis, including practical implementation, case studies, and future directions.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
This article discusses Monte Carlo dropout and how it is used to estimate uncertainty in multi-class neural network classification, covering methods such as entropy, variance, and predictive probabilities.
PDEs offer a powerful framework for understanding complex systems in fields like physics, finance, and environmental science. Discover how data scientists can integrate PDEs with modern machine learning techniques to create robust predictive models.
Learn how data science revolutionizes predictive maintenance through key techniques like regression, anomaly detection, and clustering to forecast machine failures and optimize maintenance schedules.
A comparison between machine learning models and univariate time series models for predicting emergency department visit volumes, focusing on predictive accuracy.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
Machine learning is transforming climate science, offering powerful predictive tools for forecasting extreme weather, rising sea levels, and biodiversity shifts.
Explore the role of data science in predictive maintenance, from forecasting equipment failure to optimizing maintenance schedules using techniques like regression and anomaly detection.
Machine learning is often seen as a new frontier, but its roots lie firmly in traditional statistical methods. This article explores how statistical techniques underpin key machine learning algorithms, highlighting their interconnectedness.
Deploying machine learning models to production requires planning and robust infrastructure. Here are key practices to ensure success.
Mastering mathematics and statistics is essential for understanding data science algorithms and avoiding common pitfalls when building models.
Discover the essential steps of Exploratory Data Analysis (EDA) and how to gain insights from your data before building models.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
Data science is transforming our approach to antibiotic resistance by identifying patterns in antibiotic use, proposing interventions, and aiding in the fight against superbugs.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Predictive analytics in healthcare is transforming how providers foresee health problems using machine learning and patient data. This article discusses key use cases such as hospital readmissions and chronic disease management.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
A data-driven business strategy integrates Business Intelligence and Data Science to drive informed decisions, optimize resources, and stay competitive.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
This article explores the often-overlooked importance of data quality in the data industry and emphasizes the urgent need for defined roles in data design, collection, and quality assurance.
Imagine building a model to predict house prices based on features like size, location, and amenities. If you accidentally include the actual selling price during training, the model learns this private information instead of the underlying patterns in the other features. This is data leakage, co...
Machine learning models are trained with historical data, but once they are used in the real world, they may become outdated and lose their accuracy over time due to a phenomenon called drift. Drift is the change over time in the statistical properties of the data that was used to train a machine...
1. Introduction
Introduction
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Stepwise Regression
Introduction
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Exploring Climate Value at Risk (VaR) from a data science perspective, detailing its role in assessing financial risks associated with climate change.
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
While engineering projects have defined solutions and known processes, data science is all about experimentation and discovery. Managing them in the same way can be detrimental.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Delve into the fears and complexities of artificial intelligence and automation, addressing concerns like job displacement, data privacy, ethical decision-making, and the true capabilities and limitations of AI.
A deep dive into the ethical challenges of data science, covering privacy, bias, social impact, and the need for responsible AI decision-making.
Discover how data science, a multidisciplinary field combining statistics, computer science, and domain expertise, can drive better business decisions and outcomes.
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Spatial epidemiology combines geospatial data with data science techniques to track and analyze disease outbreaks, offering public health agencies critical tools for intervention and planning.
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Discover how data science enhances supply chain optimization and industrial network analysis, leveraging techniques like predictive analytics, machine learning, and graph theory to optimize operations.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
Learn how to avoid false positives and false negatives in hypothesis testing by understanding Type I and Type II errors, their causes, and how to balance statistical power and sample size.
Bayesian data science offers a powerful framework for incorporating prior knowledge into statistical analysis, improving predictions, and informing decisions in a probabilistic manner.
Learn how data science revolutionizes predictive maintenance through key techniques like regression, anomaly detection, and clustering to forecast machine failures and optimize maintenance schedules.
Discover best practices for creating clear and compelling data visualizations that communicate insights effectively.
Understand how simple linear regression models the relationship between two variables using a single predictor.
An introduction to probability theory concepts every data scientist should know.
Data science is a key driver of sustainability, offering insights that help optimize resources, reduce waste, and improve the energy efficiency of supply chains.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
Understand how causal reasoning helps us move beyond correlation, resolving paradoxes and leading to more accurate insights from data analysis.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Machine learning is often seen as a new frontier, but its roots lie firmly in traditional statistical methods. This article explores how statistical techniques underpin key machine learning algorithms, highlighting their interconnectedness.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
Moving averages are a cornerstone of stock trading, renowned for their ability to illuminate price trends by filtering out short-term volatility. But the utility of moving averages extends far beyond the financial markets. When applied to the analysis of individual behavior, moving averages offer...
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Outlier detection is a critical task in machine learning, particularly within unsupervised learning, where data labels are absent. The goal is to identify items in a dataset that deviate significantly from the norm. This technique is essential across numerous domains, including fraud detection, s...
Overview of the Counts Outliers Detector (COD)
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
Dive into the nuances of sample size in statistical analysis, challenging the common belief that larger samples always lead to better results.
Data and communication are intricately linked in modern business. This article explores how to balance data analysis with storytelling, ensuring clear and actionable insights.
Discover how data science, a multidisciplinary field combining statistics, computer science, and domain expertise, can drive better business decisions and outcomes.
Understand key probability distributions in machine learning and their applications, including Bernoulli, Gaussian, and Beta distributions.
Learn how time series decomposition reveals trend, seasonality, and residual components for clearer forecasting insights.
Discover the universal structure behind statistical tests, highlighting the core comparison between observed and expected data that drives hypothesis testing and data analysis.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
Explore the architecture of ordinal regression models, their applications in real-world data, and how marginal effects enhance the interpretability of complex models using Python.
Dive into the intricacies of describing distributions, understand the mathematics behind common distributions, and see their applications in parametric statistics across multiple disciplines.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Basics of the Logrank Test
Stepwise Regression
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
runner Package
Explore the runner package in R, which allows applying any R function to rolling windows of data with full control over window size, lags, and index types.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
Learn the fundamentals of ARIMA modeling for time series analysis. This guide covers the AR, I, and MA components, model identification, validation, and its comparison with other models.
Learn what the False Positive Rate (FPR) is, how it impacts machine learning models, and when to use it for better evaluation.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Mastering mathematics and statistics is essential for understanding data science algorithms and avoiding common pitfalls when building models.
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
Stepwise Regression
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
This article delves into the core mathematical principles behind machine learning, including classification and regression settings, loss functions, risk minimization, decision trees, and more.
See how hypothesis testing helps draw meaningful conclusions from data in practical scenarios.
Explore the fundamentals of Bayesian inference and how prior beliefs combine with data to form posterior conclusions.
Understand how simple linear regression models the relationship between two variables using a single predictor.
An introduction to probability theory concepts every data scientist should know.
Learn the key differences between ANOVA and Kruskal-Wallis tests, and understand when to use each method based on your data’s assumptions and characteristics.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Machine learning is often seen as a new frontier, but its roots lie firmly in traditional statistical methods. This article explores how statistical techniques underpin key machine learning algorithms, highlighting their interconnectedness.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Dive into the intricacies of describing distributions, understand the mathematics behind common distributions, and see their applications in parametric statistics across multiple disciplines.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
This article provides an in-depth comparison between the t-test and z-test, highlighting their differences, appropriate usage, and real-world applications, with examples of one-sample, two-sample, and paired t-tests.
Explore the challenges of using traditional hypothesis testing for detecting data drift in machine learning models and learn how Bayesian probability offers a more robust alternative for monitoring data shifts.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
In statistics, probability distributions are essential for determining the probabilities of various outcomes in an experiment. They provide the mathematical framework to describe how data behaves under different conditions and assumptions. This is particularly important in clinical trials, where ...
Basics of the Logrank Test
Sunrise in Lisbon Harbour, December 2020
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
Explore the Wald test, a key tool in hypothesis testing for regression models, its applications, and its role in logistic regression, Poisson regression, and beyond.
Learn how to avoid false positives and false negatives in hypothesis testing by understanding Type I and Type II errors, their causes, and how to balance statistical power and sample size.
See how hypothesis testing helps draw meaningful conclusions from data in practical scenarios.
The Mann-Whitney U test and independent t-test are used for comparing two independent groups, but the choice between them depends on data distribution. Learn when to use each and explore real-world applications.
Explore Type I and Type II errors in hypothesis testing. Learn how to balance error rates, interpret significance levels, and understand the implications of statistical errors in real-world scenarios.
A detailed look at hypothesis testing, the misconceptions around the null hypothesis, and the diverse methods for detecting data deviations.
Learn the key differences between ANOVA and Kruskal-Wallis tests, and understand when to use each method based on your data’s assumptions and characteristics.
Before applying the Box-Cox transformation, it is crucial to consider its implications on model assumptions, interpretation, and hypothesis testing. This article explores 12 critical questions you should ask yourself before using the transformation.
One-way and two-way ANOVA are essential tools for comparing means across groups, but each test serves different purposes. Learn when to use one-way versus two-way ANOVA and how to interpret their results.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
Discover incremental learning in time series forecasting, a technique that dynamically updates models with new data for better accuracy and efficiency.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
Introduction
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Multicollinearity is a common issue in regression analysis. Learn about its implications, misconceptions, and techniques to manage it in statistical modeling.
Introduction
Introduction
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
Both linear and logistic models offer unique advantages depending on the circumstances. Learn when each model is appropriate and how to interpret their results.
runner Package
Explore the runner package in R, which allows applying any R function to rolling windows of data with full control over window size, lags, and index types.
Polynomial regression is a popular extension of linear regression that models nonlinear relationships between the response and explanatory variables. However, despite its name, polynomial regression remains a form of linear regression, as the response variable is still a linear combination of the...
Bayesian data science offers a powerful framework for incorporating prior knowledge into statistical analysis, improving predictions, and informing decisions in a probabilistic manner.
This article explores the use of stationary distributions in time series models to define thresholds in zero-inflated data, improving classification accuracy.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
Before applying the Box-Cox transformation, it is crucial to consider its implications on model assumptions, interpretation, and hypothesis testing. This article explores 12 critical questions you should ask yourself before using the transformation.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
Statistical models lie at the heart of modern data science and quantitative research, enabling analysts to infer, predict, and simulate outcomes from structured data.
Machine learning models are revolutionizing post-hospitalization care by predicting hospital readmissions in elderly patients, helping healthcare providers optimize treatment and reduce complications.
Data science is revolutionizing chronic disease management among the elderly by leveraging predictive analytics to monitor disease progression, manage medications, and create personalized treatment plans.
Predictive analytics in healthcare is transforming how providers foresee health problems using machine learning and patient data. This article discusses key use cases such as hospital readmissions and chronic disease management.
A data-driven business strategy integrates Business Intelligence and Data Science to drive informed decisions, optimize resources, and stay competitive.
The fusion of Business Intelligence and Machine Learning offers a pathway from historical analysis to predictive and prescriptive decision-making.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Introduction
A detailed exploration of Customer Lifetime Value (CLV) for data practitioners and marketers, including its calculation, prediction, and integration with other business data.
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Big data is revolutionizing climate science, enabling more accurate predictions and helping formulate effective mitigation strategies.
Time series analysis is a vital tool in epidemiology, allowing researchers to model the spread of diseases, detect outbreaks, and predict future trends in infection rates.
Machine learning is transforming climate science, offering powerful predictive tools for forecasting extreme weather, rising sea levels, and biodiversity shifts.
Explore the role of data science in predictive maintenance, from forecasting equipment failure to optimizing maintenance schedules using techniques like regression and anomaly detection.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Introduction
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Stepwise Regression
Abstract
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
A detailed look at hypothesis testing, the misconceptions around the null hypothesis, and the diverse methods for detecting data deviations.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
This article provides an in-depth comparison between the t-test and z-test, highlighting their differences, appropriate usage, and real-world applications, with examples of one-sample, two-sample, and paired t-tests.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
Introduction
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Abstract
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
Mastering mathematics and statistics is essential for understanding data science algorithms and avoiding common pitfalls when building models.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Explore how mathematics shapes modern society across fields like technology, education, and problem-solving. This article delves into the often overlooked impact of mathematics on innovation and societal progress.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
Dive into the world of calculus, where derivatives and integrals are used to analyze change and calculate areas under curves. Learn about these fundamental tools and their wide-ranging applications.
Data drift is one of the primary threats to model reliability in production. This article walks through how to detect it using both statistical techniques and modern monitoring tools.
Even the best machine learning models experience performance degradation over time due to model drift. Learn about the causes of model drift and how it affects production systems.
Data drift can significantly affect the performance of machine learning models over time. Learn about different types of drift and how they impact model predictions in dynamic environments.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Learn how to manage covariate shifts in machine learning models through effective model monitoring, feature engineering, and adaptation strategies to maintain model accuracy and performance.
Explore the challenges of using traditional hypothesis testing for detecting data drift in machine learning models and learn how Bayesian probability offers a more robust alternative for monitoring data shifts.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Machine learning models degrade over time due to model drift, which includes data drift, concept drift, and feature drift. Learn how to detect, measure, and mitigate these challenges.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
Outlier detection is a critical task in machine learning, particularly within unsupervised learning, where data labels are absent. The goal is to identify items in a dataset that deviate significantly from the norm. This technique is essential across numerous domains, including fraud detection, s...
Principal Component Analysis (PCA) is a robust technique used for dimensionality reduction while retaining critical information in datasets. Its sensitivity makes it particularly useful for detecting outliers in multivariate datasets. Detecting outliers can provide early warnings of abnormal cond...
Overview of the Counts Outliers Detector (COD)
Outlier detection presents significant challenges, particularly in evaluating the effectiveness of outlier detection algorithms. Traditional methods of evaluation, such as those used in predictive modeling, are often inapplicable due to the lack of labeled data. This article introduces a method k...
1. Introduction
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Statistical models lie at the heart of modern data science and quantitative research, enabling analysts to infer, predict, and simulate outcomes from structured data.
Statistical AI leverages probabilistic reasoning and data-driven inference to build adaptive and intelligent systems.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
Normal Distribution: Explained
Introduction
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Bayesian data science offers a powerful framework for incorporating prior knowledge into statistical analysis, improving predictions, and informing decisions in a probabilistic manner.
An introduction to probability theory concepts every data scientist should know.
Learn specialized feature engineering techniques to make time series data more predictive for machine learning models.
Explore how simple distributional models for time-series classification can be extended with additional feature sets like catch22 to improve performance without sacrificing interpretability.
Feature engineering is crucial in machine learning, but it’s easy to make mistakes that lead to inaccurate models. This article highlights five common pitfalls and provides strategies to avoid them.
Learn how to manage covariate shifts in machine learning models through effective model monitoring, feature engineering, and adaptation strategies to maintain model accuracy and performance.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
Explore feature discretization as a powerful technique to enhance linear models, bridging the gap between linear precision and non-linear complexity in data analysis.
Learn how to design robust data preprocessing pipelines that prepare raw data for modeling.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
This review explores the transformative applications of mathematical optimization and machine learning in industrial management, with a focus on production planning, predictive maintenance, and supply chain optimization.
A data-driven investigation into predictive maintenance’s operational value across industries, exploring statistical models, machine learning architectures, and real-world results.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
Statistical AI leverages probabilistic reasoning and data-driven inference to build adaptive and intelligent systems.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
A practical introduction to building ARIMA models in Python for reliable time series forecasting.
Learn specialized feature engineering techniques to make time series data more predictive for machine learning models.
Explore the critical role of Bayesian state space models in macroeconometric analysis, with a focus on linear Gaussian models, dimension reduction, and non-linear or non-Gaussian extensions.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
Dive into Gaussian Processes for time-series analysis using Python, combining flexible modeling with Bayesian inference for trends, seasonality, and noise.
Learn how time series decomposition reveals trend, seasonality, and residual components for clearer forecasting insights.
This article explores the use of stationary distributions in time series models to define thresholds in zero-inflated data, improving classification accuracy.
Learn the fundamentals of ARIMA modeling for time series analysis. This guide covers the AR, I, and MA components, model identification, validation, and its comparison with other models.
This in-depth guide explains heteroscedasticity in data analysis, highlighting its implications and techniques to manage non-constant variance.
Multicollinearity is a common issue in regression analysis. Learn about its implications, misconceptions, and techniques to manage it in statistical modeling.
Stepwise Regression
Abstract
Regression and path analysis are two statistical techniques used to model relationships between variables. This article explains their differences, highlighting key features and use cases for each.
A deep dive into the relationship between OLS and Theil-Sen estimators, revealing their connection through weighted averages and robust median-based slopes.
Polynomial regression is a popular extension of linear regression that models nonlinear relationships between the response and explanatory variables. However, despite its name, polynomial regression remains a form of linear regression, as the response variable is still a linear combination of the...
Heteroscedasticity can affect regression models, leading to biased or inefficient estimates. Here’s how to detect it and what to do when it’s present.
Unlock the power of Bayesian statistics in machine learning through probabilistic reasoning, offering insights into model uncertainty, predictive distributions, and real-world applications.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
The History of Artificial Intelligence
Delve into the fears and complexities of artificial intelligence and automation, addressing concerns like job displacement, data privacy, ethical decision-making, and the true capabilities and limitations of AI.
A deep dive into the ethical challenges of data science, covering privacy, bias, social impact, and the need for responsible AI decision-making.
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Data science is transforming our approach to antibiotic resistance by identifying patterns in antibiotic use, proposing interventions, and aiding in the fight against superbugs.
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
Introduction
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Stepwise Regression
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
Introduction
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
runner Package
Explore the runner package in R, which allows applying any R function to rolling windows of data with full control over window size, lags, and index types.
Time series analysis is a vital tool in epidemiology, allowing researchers to model the spread of diseases, detect outbreaks, and predict future trends in infection rates.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
Most diagrams for choosing statistical tests miss the bigger picture. Here’s a bold, practical approach that emphasizes interpretation over mechanistic rules, and cuts through statistical misconceptions like the N>30 rule.
AI and machine learning are transforming renewable energy systems, making them more efficient, reliable, and sustainable. Learn how intelligent technologies are powering the clean energy transition.
A practical introduction to building ARIMA models in Python for reliable time series forecasting.
Learn specialized feature engineering techniques to make time series data more predictive for machine learning models.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
Learn how time series decomposition reveals trend, seasonality, and residual components for clearer forecasting insights.
Learn the fundamentals of ARIMA modeling for time series analysis. This guide covers the AR, I, and MA components, model identification, validation, and its comparison with other models.
In statistics, probability distributions are essential for determining the probabilities of various outcomes in an experiment. They provide the mathematical framework to describe how data behaves under different conditions and assumptions. This is particularly important in clinical trials, where ...
Introduction
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Understand key probability distributions in machine learning and their applications, including Bernoulli, Gaussian, and Beta distributions.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
Unlock the power of Bayesian statistics in machine learning through probabilistic reasoning, offering insights into model uncertainty, predictive distributions, and real-world applications.
Introduction
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Bayesian data science offers a powerful framework for incorporating prior knowledge into statistical analysis, improving predictions, and informing decisions in a probabilistic manner.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
COPOD is a popular anomaly detection model, but how well does it perform in practice? This article discusses critical validation issues in third-party models and lessons learned from COPOD.
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
Principal Component Analysis (PCA) is a robust technique used for dimensionality reduction while retaining critical information in datasets. Its sensitivity makes it particularly useful for detecting outliers in multivariate datasets. Detecting outliers can provide early warnings of abnormal cond...
1. Introduction
Discover critical lessons learned from validating COPOD, a popular anomaly detection model, through test-driven validation techniques. Avoid common pitfalls in anomaly detection modeling.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Sunrise in Lisbon Harbour, December 2020
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
The log-rank test is a key tool in survival analysis, commonly used to compare survival curves between groups in medical research. Learn how it works and how to interpret its results.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
The Log-Rank test is a vital statistical method used to compare survival curves in clinical studies. This article explores its significance in medical research, including applications in clinical trials and epidemiology.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Learn about the Shapiro-Wilk and Anderson-Darling tests for normality, their differences, and how they guide decisions between parametric and non-parametric statistical methods.
Learn the key differences between ANOVA and Kruskal-Wallis tests, and understand when to use each method based on your data’s assumptions and characteristics.
A practical introduction to building ARIMA models in Python for reliable time series forecasting.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
Learn the fundamentals of ARIMA modeling for time series analysis. This guide covers the AR, I, and MA components, model identification, validation, and its comparison with other models.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
An exploration of cross-validation techniques in machine learning, focusing on methods to evaluate and enhance model performance while mitigating overfitting risks.
Outlier detection presents significant challenges, particularly in evaluating the effectiveness of outlier detection algorithms. Traditional methods of evaluation, such as those used in predictive modeling, are often inapplicable due to the lack of labeled data. This article introduces a method k...
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn what the False Positive Rate (FPR) is, how it impacts machine learning models, and when to use it for better evaluation.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Introduction
Introduction
Both linear and logistic models offer unique advantages depending on the circumstances. Learn when each model is appropriate and how to interpret their results.
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
Explore the Wald test, a key tool in hypothesis testing for regression models, its applications, and its role in logistic regression, Poisson regression, and beyond.
Understand Cochran’s Q test, a non-parametric test for comparing proportions across related groups, and its applications in binary data and its connection to McNemar’s test.
Overview of the Counts Outliers Detector (COD)
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Learn the core concepts of binary classification, explore common algorithms like Decision Trees and SVMs, and discover how to evaluate performance using precision, recall, and F1-score.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
Polynomial regression is a popular extension of linear regression that models nonlinear relationships between the response and explanatory variables. However, despite its name, polynomial regression remains a form of linear regression, as the response variable is still a linear combination of the...
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
Machine learning models are revolutionizing post-hospitalization care by predicting hospital readmissions in elderly patients, helping healthcare providers optimize treatment and reduce complications.
The integration of IoT and big data is revolutionizing elderly care by enabling remote monitoring systems that track vital signs, detect emergencies, and ensure quick responses to health risks.
Data science is revolutionizing chronic disease management among the elderly by leveraging predictive analytics to monitor disease progression, manage medications, and create personalized treatment plans.
Machine learning is revolutionizing fall prevention in elderly care by predicting the likelihood of falls through wearable sensor data, mobility analysis, and health history insights.
As AI revolutionizes elderly care, ethical concerns around privacy, autonomy, and consent come into focus. This article explores how to balance technological advancements with the dignity and personal preferences of elderly individuals.
Least Angle Regression, or LARS, is an efficient regression algorithm designed for high-dimensional data. It provides a pathwise approach to linear regression that is especially useful in the presence of multicollinearity or when feature selection is crucial.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
Understand how simple linear regression models the relationship between two variables using a single predictor.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Mastering mathematics and statistics is essential for understanding data science algorithms and avoiding common pitfalls when building models.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
This article delves into the core mathematical principles behind machine learning, including classification and regression settings, loss functions, risk minimization, decision trees, and more.
Machine learning is often seen as a new frontier, but its roots lie firmly in traditional statistical methods. This article explores how statistical techniques underpin key machine learning algorithms, highlighting their interconnectedness.
Explore the key concepts of Mean Time Between Failures (MTBF), how it is calculated, its applications, and its alternatives in system reliability.
Learn how IoT-enabled sensors like vibration, temperature, and pressure sensors gather crucial data for predictive maintenance, allowing for real-time monitoring and more effective maintenance strategies.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
Learn how data science revolutionizes predictive maintenance through key techniques like regression, anomaly detection, and clustering to forecast machine failures and optimize maintenance schedules.
Explore the role of data science in predictive maintenance, from forecasting equipment failure to optimizing maintenance schedules using techniques like regression and anomaly detection.
Dive into the Chi-Square Test, a statistical method for evaluating categorical data. Understand its applications in survey analysis, contingency tables, and genetics.
Basics of the Logrank Test
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
The Chi-Square Test is a powerful tool for analyzing relationships in categorical data. Learn its principles and practical applications.
This article delves into the Chi-Square test, a fundamental tool for analyzing categorical data, with a focus on its applications in goodness-of-fit and tests of independence.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Abstract
Learn the key differences between MANOVA and ANOVA, and when to apply them in experimental designs with multiple dependent variables, such as clinical trials.
Levene’s Test and Bartlett’s Test are key tools for checking homogeneity of variances in data. Learn when to use each test, based on normality assumptions, and how they relate to tests like ANOVA.
Learn the key differences between ANOVA and Kruskal-Wallis tests, and understand when to use each method based on your data’s assumptions and characteristics.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Statistical estimates always have some uncertainty. Consider a simple example of modeling house prices based solely on their area using linear regression. A prediction from this model wouldn’t reveal the exact value of a house based on its area, because different houses of the same size can have ...
A step-by-step guide to implementing Linear Regression from scratch using the Normal Equation method, complete with Python code and evaluation techniques.
Polynomial regression is a popular extension of linear regression that models nonlinear relationships between the response and explanatory variables. However, despite its name, polynomial regression remains a form of linear regression, as the response variable is still a linear combination of the...
Discover the foundations of Ordinary Least Squares (OLS) regression, its key properties such as consistency, efficiency, and maximum likelihood estimation, and its applications in linear modeling.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
PDEs offer a powerful framework for understanding complex systems in fields like physics, finance, and environmental science. Discover how data scientists can integrate PDEs with modern machine learning techniques to create robust predictive models.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Statistical models lie at the heart of modern data science and quantitative research, enabling analysts to infer, predict, and simulate outcomes from structured data.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Delve into how multiple linear regression and binary logistic regression handle errors. Learn about explicit and implicit error terms and their impact on model performance.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
Explore the architecture of ordinal regression models, their applications in real-world data, and how marginal effects enhance the interpretability of complex models using Python.
An exploration of cross-validation techniques in machine learning, focusing on methods to evaluate and enhance model performance while mitigating overfitting risks.
Stepwise Regression
Introduction
Understand how decision tree algorithms split data and how pruning improves generalization.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
KMeans is widely used, but it’s not always the best clustering algorithm for your data. Explore alternative methods like Gaussian Mixture Models and other clustering techniques to improve your machine learning results.
Outlier detection is a critical task in machine learning, particularly within unsupervised learning, where data labels are absent. The goal is to identify items in a dataset that deviate significantly from the norm. This technique is essential across numerous domains, including fraud detection, s...
1. Introduction
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Explore the differences between ROC AUC and Precision-Recall AUC in machine learning and learn when to use each metric for classification tasks.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Data drift is one of the primary threats to model reliability in production. This article walks through how to detect it using both statistical techniques and modern monitoring tools.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Learn how to manage covariate shifts in machine learning models through effective model monitoring, feature engineering, and adaptation strategies to maintain model accuracy and performance.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Sunrise in Lisbon Harbour, December 2020
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
This article rigorously explores the Central Limit Theorem for m-dependent random variables under sub-linear expectations, presenting new inequalities, proof outlines, and implications in modeling dependent sequences.
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
Normal Distribution: Explained
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
Least Angle Regression, or LARS, is an efficient regression algorithm designed for high-dimensional data. It provides a pathwise approach to linear regression that is especially useful in the presence of multicollinearity or when feature selection is crucial.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
Introduction
Introduction
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
John Nash revolutionized game theory with his Nash equilibrium concept and won the Nobel Prize in Economics. He also faced a lifelong struggle with schizophrenia, making his life a story of genius, triumph, and resilience.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
Delve into the fascinating life of Paul Erdős, a wandering mathematician whose love for numbers and collaboration reshaped the world of mathematics.
Julia Robinson was a trailblazing mathematician known for her work on decision problems and number theory. She played a crucial role in solving Hilbert’s Tenth Problem and became the first woman elected to the National Academy of Sciences.
Sophie Germain was a trailblazing mathematician who made groundbreaking contributions to number theory and elasticity. This article explores her life, her challenges, and her lasting impact on mathematics and science.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Even the best machine learning models experience performance degradation over time due to model drift. Learn about the causes of model drift and how it affects production systems.
Machine learning models are trained with historical data, but once they are used in the real world, they may become outdated and lose their accuracy over time due to a phenomenon called drift. Drift is the change over time in the statistical properties of the data that was used to train a machine...
Machine learning models degrade over time due to model drift, which includes data drift, concept drift, and feature drift. Learn how to detect, measure, and mitigate these challenges.
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
Exploring Climate Value at Risk (VaR) from a data science perspective, detailing its role in assessing financial risks associated with climate change.
Big data is revolutionizing climate science, enabling more accurate predictions and helping formulate effective mitigation strategies.
Machine learning is transforming climate science, offering powerful predictive tools for forecasting extreme weather, rising sea levels, and biodiversity shifts.
Dive into the Chi-Square Test, a statistical method for evaluating categorical data. Understand its applications in survey analysis, contingency tables, and genetics.
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
The Chi-Square Test is a powerful tool for analyzing relationships in categorical data. Learn its principles and practical applications.
This article delves into the Chi-Square test, a fundamental tool for analyzing categorical data, with a focus on its applications in goodness-of-fit and tests of independence.
Dive into the Chi-Square Test, a statistical method for evaluating categorical data. Understand its applications in survey analysis, contingency tables, and genetics.
The Chi-Square Test is a powerful tool for analyzing relationships in categorical data. Learn its principles and practical applications.
This article delves into the Chi-Square test, a fundamental tool for analyzing categorical data, with a focus on its applications in goodness-of-fit and tests of independence.
In statistics, probability distributions are essential for determining the probabilities of various outcomes in an experiment. They provide the mathematical framework to describe how data behaves under different conditions and assumptions. This is particularly important in clinical trials, where ...
Learn the key differences between MANOVA and ANOVA, and when to apply them in experimental designs with multiple dependent variables, such as clinical trials.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
The Log-Rank test is a vital statistical method used to compare survival curves in clinical studies. This article explores its significance in medical research, including applications in clinical trials and epidemiology.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
The Mann-Whitney U test and independent t-test are used for comparing two independent groups, but the choice between them depends on data distribution. Learn when to use each and explore real-world applications.
Understand Cochran’s Q test, a non-parametric test for comparing proportions across related groups, and its applications in binary data and its connection to McNemar’s test.
The Friedman test is a non-parametric alternative to repeated measures ANOVA, designed for use with ordinal data or non-normal distributions. Learn how and when to use it in your analyses.
Introduction
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Learn the core concepts of binary classification, explore common algorithms like Decision Trees and SVMs, and discover how to evaluate performance using precision, recall, and F1-score.
Learn what the False Positive Rate (FPR) is, how it impacts machine learning models, and when to use it for better evaluation.
This article explores the often-overlooked importance of data quality in the data industry and emphasizes the urgent need for defined roles in data design, collection, and quality assurance.
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Understanding coverage probability in statistical estimation and prediction: its role in constructing confidence intervals and assessing their accuracy.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
Data drift is one of the primary threats to model reliability in production. This article walks through how to detect it using both statistical techniques and modern monitoring tools.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Discover the universal structure behind statistical tests, highlighting the core comparison between observed and expected data that drives hypothesis testing and data analysis.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
The integration of IoT and big data is revolutionizing elderly care by enabling remote monitoring systems that track vital signs, detect emergencies, and ensure quick responses to health risks.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
This article explores the fundamentals of data engineering, including the ETL/ELT processes, required skills, and the relationship with data science.
Big data is revolutionizing climate science, enabling more accurate predictions and helping formulate effective mitigation strategies.
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Fundamental research is often targeted for cuts due to its lack of immediate outcomes. But eliminating it risks innovation, education, crisis response, and global competitiveness.
Explore how mathematics shapes modern society across fields like technology, education, and problem-solving. This article delves into the often overlooked impact of mathematics on innovation and societal progress.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
The integration of IoT and big data is revolutionizing elderly care by enabling remote monitoring systems that track vital signs, detect emergencies, and ensure quick responses to health risks.
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
Learn how IoT-enabled sensors like vibration, temperature, and pressure sensors gather crucial data for predictive maintenance, allowing for real-time monitoring and more effective maintenance strategies.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Principal Component Analysis (PCA) is a robust technique used for dimensionality reduction while retaining critical information in datasets. Its sensitivity makes it particularly useful for detecting outliers in multivariate datasets. Detecting outliers can provide early warnings of abnormal cond...
Abstract
Learn about Principal Component Analysis (PCA) and how it helps in feature extraction, dimensionality reduction, and identifying key patterns in data.
Introduction
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Learn about Principal Component Analysis (PCA) and how it helps in feature extraction, dimensionality reduction, and identifying key patterns in data.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
Dive into the fascinating world of pedestrian behavior through mathematical models like the Social Force Model. Learn how these models inform urban planning, crowd management, and traffic control for safer and more efficient public spaces.
Even the best machine learning models experience performance degradation over time due to model drift. Learn about the causes of model drift and how it affects production systems.
Data drift can significantly affect the performance of machine learning models over time. Learn about different types of drift and how they impact model predictions in dynamic environments.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
An in-depth exploration of how the closure of open-source data platforms threatens the growth of Large Language Models and the vital role humans play in this ecosystem.
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Abstract
Introduction
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Discover how AI-powered tools are reshaping mental health care for older adults, offering early detection, personalized mood tracking, cognitive monitoring, and integrated clinical support.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
KMeans is widely used, but it’s not always the best clustering algorithm for your data. Explore alternative methods like Gaussian Mixture Models and other clustering techniques to improve your machine learning results.
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
A complete guide to writing the sample size justification section for your clinical trial protocol, covering key statistical concepts like power, error thresholds, and outcome assumptions.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Hyperparameter tuning can drastically improve model performance. Explore common search strategies and tools.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
Learn how machine learning optimizes supply chain operations by enhancing demand forecasting, inventory management, logistics, and more, driving efficiency and business value.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Explore time-series classification in Python with step-by-step examples using simple models, the catch22 feature set, and UEA/UCR repository benchmarking with statistical tests.
Explore how simple distributional models for time-series classification can be extended with additional feature sets like catch22 to improve performance without sacrificing interpretability.
A comprehensive review of simple distributional properties such as mean and standard deviation as a strong baseline for time-series classification in standardized benchmarks.
An in-depth review of the role of simple distributional properties, like mean and standard deviation, in time-series classification as a baseline approach.
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
Understand how causal reasoning helps us move beyond correlation, resolving paradoxes and leading to more accurate insights from data analysis.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Mary Somerville’s work in astronomy and mathematical physics earned her recognition as one of the first female scientists, making complex scientific concepts accessible.
Hypatia of Alexandria is recognized as the first known female mathematician. This article explores her contributions to geometry and astronomy, her philosophical influence, and her tragic death.
Sophie Germain was a trailblazing mathematician who made groundbreaking contributions to number theory and elasticity. This article explores her life, her challenges, and her lasting impact on mathematics and science.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Ada Lovelace is celebrated as the first computer programmer for her visionary work on Charles Babbage’s Analytical Engine. Discover her pioneering insights into computational theory, which laid the foundation for modern computing.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
Hypatia of Alexandria is recognized as the first known female mathematician. This article explores her contributions to geometry and astronomy, her philosophical influence, and her tragic death.
David Hilbert, one of the most influential mathematicians of the 20th century, is best known for his ‘Hilbert Problems’ and his pioneering contributions to algebra, geometry, and logic. This article examines his lasting impact on mathematics.
Learn about the Shapiro-Wilk and Anderson-Darling tests for normality, their differences, and how they guide decisions between parametric and non-parametric statistical methods.
The Kolmogorov-Smirnov test is a powerful tool for assessing goodness-of-fit in non-parametric data. Learn how it works, how it compares to the Shapiro-Wilk test, and explore real-world applications.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
Data drift can significantly affect the performance of machine learning models over time. Learn about different types of drift and how they impact model predictions in dynamic environments.
Machine learning models degrade over time due to model drift, which includes data drift, concept drift, and feature drift. Learn how to detect, measure, and mitigate these challenges.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
Explore the Granger causality test, a vital tool for determining causal relationships in time-series data across various domains, including economics, climate science, and finance.
Heteroscedasticity can affect regression models, leading to biased or inefficient estimates. Here’s how to detect it and what to do when it’s present.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
Learn how to avoid false positives and false negatives in hypothesis testing by understanding Type I and Type II errors, their causes, and how to balance statistical power and sample size.
This article delves into the Chi-Square test, a fundamental tool for analyzing categorical data, with a focus on its applications in goodness-of-fit and tests of independence.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Basics of the Logrank Test
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
A comparison between machine learning models and univariate time series models for predicting emergency department visit volumes, focusing on predictive accuracy.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
An exploration of cross-validation techniques in machine learning, focusing on methods to evaluate and enhance model performance while mitigating overfitting risks.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Statistical models lie at the heart of modern data science and quantitative research, enabling analysts to infer, predict, and simulate outcomes from structured data.
Bayesian data science offers a powerful framework for incorporating prior knowledge into statistical analysis, improving predictions, and informing decisions in a probabilistic manner.
Explore the fundamentals of Bayesian inference and how prior beliefs combine with data to form posterior conclusions.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Maryam Mirzakhani made history as the first woman to win the Fields Medal for her groundbreaking work on the geometry of Riemann surfaces. Her contributions continue to inspire mathematicians today.
Julia Robinson was a trailblazing mathematician known for her work on decision problems and number theory. She played a crucial role in solving Hilbert’s Tenth Problem and became the first woman elected to the National Academy of Sciences.
Machine learning is revolutionizing forest fire management through advanced models, real-time data integration, and emerging technologies like IoT and blockchain, offering a holistic and adaptive strategy for combating forest fires.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Feature engineering is crucial in machine learning, but it’s easy to make mistakes that lead to inaccurate models. This article highlights five common pitfalls and provides strategies to avoid them.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
Learn how to design robust data preprocessing pipelines that prepare raw data for modeling.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
A deep dive into using Genetic Algorithms to create more accurate, interpretable decision trees for classification tasks.
Understand how decision tree algorithms split data and how pruning improves generalization.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
Understand how decision tree algorithms split data and how pruning improves generalization.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Linear Programming is the foundation of optimization in operations research. We explore its traditional methods, challenges in scaling large instances, and introduce PDLP, a scalable solver using first-order methods, designed for modern computational infrastructures.
Even the best machine learning models experience performance degradation over time due to model drift. Learn about the causes of model drift and how it affects production systems.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Learn how graph theory is applied to network analysis in production systems to optimize processes, identify bottlenecks, and improve supply chain efficiency.
Least Angle Regression, or LARS, is an efficient regression algorithm designed for high-dimensional data. It provides a pathwise approach to linear regression that is especially useful in the presence of multicollinearity or when feature selection is crucial.
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
Explore feature discretization as a powerful technique to enhance linear models, bridging the gap between linear precision and non-linear complexity in data analysis.
There is a clear reason why stepwise regression is usually inappropriate, along with several other significant drawbacks. This article will delve into these issues, providing an in-depth understanding of why stepwise selection is generally detrimental to statistical estimates.
Delve into how multiple linear regression and binary logistic regression handle errors. Learn about explicit and implicit error terms and their impact on model performance.
Explore the Wald test, a key tool in hypothesis testing for regression models, its applications, and its role in logistic regression, Poisson regression, and beyond.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Explore the deep connection between entropy, data science, and machine learning. Understand how entropy drives decision trees, uncertainty measures, feature selection, and information theory in modern AI.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Simpson’s Paradox shows how aggregated data can lead to misleading trends. Learn the theory behind this paradox, its practical implications, and how to analyze data rigorously.
Exploring Climate Value at Risk (VaR) from a data science perspective, detailing its role in assessing financial risks associated with climate change.
A comprehensive comparison of Value at Risk (VaR) and Expected Shortfall (ES) in financial risk management, with a focus on their performance during volatile and stable market conditions.
A detailed exploration of Value at Risk (VaR), covering its different types, methods of calculation, and applications in modern portfolio management.
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Ethical considerations are critical when deploying machine learning systems that affect real people.
Delve into the fears and complexities of artificial intelligence and automation, addressing concerns like job displacement, data privacy, ethical decision-making, and the true capabilities and limitations of AI.
A deep dive into the ethical challenges of data science, covering privacy, bias, social impact, and the need for responsible AI decision-making.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Innumeracy is becoming the new illiteracy, with far-reaching implications for decision-making in various aspects of life. Discover how the inability to understand numbers affects our world and what can be done to address this growing issue.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
A comprehensive exploration of data drift in credit risk models, examining practical methods to identify and address drift using multivariate techniques.
AI and machine learning are transforming renewable energy systems, making them more efficient, reliable, and sustainable. Learn how intelligent technologies are powering the clean energy transition.
Statistical AI leverages probabilistic reasoning and data-driven inference to build adaptive and intelligent systems.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
The fusion of Business Intelligence and Machine Learning offers a pathway from historical analysis to predictive and prescriptive decision-making.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Introduction
Introduction
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
This checklist helps Data Science professionals ensure thorough validation of their projects before declaring success and deploying models.
COPOD is a popular anomaly detection model, but how well does it perform in practice? This article discusses critical validation issues in third-party models and lessons learned from COPOD.
Discover critical lessons learned from validating COPOD, a popular anomaly detection model, through test-driven validation techniques. Avoid common pitfalls in anomaly detection modeling.
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
Basics of the Logrank Test
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Sunrise in Lisbon Harbour, December 2020
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Data science is revolutionizing chronic disease management among the elderly by leveraging predictive analytics to monitor disease progression, manage medications, and create personalized treatment plans.
Predictive analytics in healthcare is transforming how providers foresee health problems using machine learning and patient data. This article discusses key use cases such as hospital readmissions and chronic disease management.
Introduction
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Absorption and Reflection
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
Nonlinear growth models offer a richer and more realistic framework for understanding macroeconomic development over time. This article explores the mathematical structures and real-world relevance of non-linear dynamics in economic growth theory.
Dynamic systems theory helps economists analyze the evolution of economic variables over time, focusing on stability and equilibrium.
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
Learn how to manage covariate shifts in machine learning models through effective model monitoring, feature engineering, and adaptation strategies to maintain model accuracy and performance.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Deploying machine learning models to production requires planning and robust infrastructure. Here are key practices to ensure success.
This article explores the fine line between Machine Learning Engineering (MLE) and MLOps roles, delving into their shared responsibilities, unique contributions, and how these roles integrate in small to large teams.
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
Neural networks power many modern AI applications. This article introduces their basic structure and training process.
Machine learning is revolutionizing medical diagnosis by providing faster, more accurate tools for detecting diseases such as cancer, heart disease, and neurological disorders.
An in-depth review of the role of simple distributional properties, like mean and standard deviation, in time-series classification as a baseline approach.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Survival analysis offers a powerful framework to model time-to-event phenomena across the supply chain. This guide explores how to apply it to inventory, perishables, shipment, equipment reliability, and supplier management.
Survival analysis offers financial institutions a powerful framework for modeling time-to-event data such as default, prepayment, and churn. This guide explores the methodology, financial applications, advanced techniques, and real-world case studies.
Survival analysis offers a powerful framework for analyzing time-to-event data in public policy, enabling data-driven decision making across health, welfare, housing, and more.
This review explores the transformative applications of mathematical optimization and machine learning in industrial management, with a focus on production planning, predictive maintenance, and supply chain optimization.
A data-driven investigation into predictive maintenance’s operational value across industries, exploring statistical models, machine learning architectures, and real-world results.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
David Hilbert, one of the most influential mathematicians of the 20th century, is best known for his ‘Hilbert Problems’ and his pioneering contributions to algebra, geometry, and logic. This article examines his lasting impact on mathematics.
Mary Somerville’s work in astronomy and mathematical physics earned her recognition as one of the first female scientists, making complex scientific concepts accessible.
Hypatia of Alexandria is recognized as the first known female mathematician. This article explores her contributions to geometry and astronomy, her philosophical influence, and her tragic death.
Learn about the Shapiro-Wilk and Anderson-Darling tests for normality, their differences, and how they guide decisions between parametric and non-parametric statistical methods.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
Dive into the nuances of sample size in statistical analysis, challenging the common belief that larger samples always lead to better results.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Let’s examine why multiple imputation, despite being popular, may not be as robust or interpretable as it’s often considered. Is there a better approach?
Let’s examine why multiple imputation, despite being popular, may not be as robust or interpretable as it’s often considered. Is there a better approach?
Let’s examine why multiple imputation, despite being popular, may not be as robust or interpretable as it’s often considered. Is there a better approach?
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Simpson’s Paradox shows how aggregated data can lead to misleading trends. Learn the theory behind this paradox, its practical implications, and how to analyze data rigorously.
Understand how causal reasoning helps us move beyond correlation, resolving paradoxes and leading to more accurate insights from data analysis.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
Learn how IoT-enabled sensors like vibration, temperature, and pressure sensors gather crucial data for predictive maintenance, allowing for real-time monitoring and more effective maintenance strategies.
Explore the role of data science in predictive maintenance, from forecasting equipment failure to optimizing maintenance schedules using techniques like regression and anomaly detection.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
Explore the role of data science in predictive maintenance, from forecasting equipment failure to optimizing maintenance schedules using techniques like regression and anomaly detection.
This in-depth guide explains heteroscedasticity in data analysis, highlighting its implications and techniques to manage non-constant variance.
Heteroscedasticity can affect regression models, leading to biased or inefficient estimates. Here’s how to detect it and what to do when it’s present.
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Before applying the Box-Cox transformation, it is crucial to consider its implications on model assumptions, interpretation, and hypothesis testing. This article explores 12 critical questions you should ask yourself before using the transformation.
The log-rank test is a key tool in survival analysis, commonly used to compare survival curves between groups in medical research. Learn how it works and how to interpret its results.
The Log-Rank test is a vital statistical method used to compare survival curves in clinical studies. This article explores its significance in medical research, including applications in clinical trials and epidemiology.
Time series analysis is a vital tool in epidemiology, allowing researchers to model the spread of diseases, detect outbreaks, and predict future trends in infection rates.
The Log-Rank test is a vital statistical method used to compare survival curves in clinical studies. This article explores its significance in medical research, including applications in clinical trials and epidemiology.
Residual diagnostics often trigger debates, especially when tests like Shapiro-Wilk suggest non-normality. But should it be the final verdict on your model? Let’s dive deeper into residual analysis, focusing on its impact in GLS, mixed models, and robust alternatives.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
A detailed look at hypothesis testing, the misconceptions around the null hypothesis, and the diverse methods for detecting data deviations.
Learn how to avoid false positives and false negatives in hypothesis testing by understanding Type I and Type II errors, their causes, and how to balance statistical power and sample size.
Explore Type I and Type II errors in hypothesis testing. Learn how to balance error rates, interpret significance levels, and understand the implications of statistical errors in real-world scenarios.
Learn how to avoid false positives and false negatives in hypothesis testing by understanding Type I and Type II errors, their causes, and how to balance statistical power and sample size.
Explore Type I and Type II errors in hypothesis testing. Learn how to balance error rates, interpret significance levels, and understand the implications of statistical errors in real-world scenarios.
Explore how graph theory is applied to optimize production systems and supply chains. Learn how network optimization and resource allocation techniques improve efficiency and streamline operations.
Data science is a key driver of sustainability, offering insights that help optimize resources, reduce waste, and improve the energy efficiency of supply chains.
An in-depth look at normality tests, their limitations, and the necessity of data visualization.
Learn about the Shapiro-Wilk and Anderson-Darling tests for normality, their differences, and how they guide decisions between parametric and non-parametric statistical methods.
Learn about the Shapiro-Wilk and Anderson-Darling tests for normality, their differences, and how they guide decisions between parametric and non-parametric statistical methods.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn what the False Positive Rate (FPR) is, how it impacts machine learning models, and when to use it for better evaluation.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
The Mann-Whitney U test and independent t-test are used for comparing two independent groups, but the choice between them depends on data distribution. Learn when to use each and explore real-world applications.
There is a clear reason why stepwise regression is usually inappropriate, along with several other significant drawbacks. This article will delve into these issues, providing an in-depth understanding of why stepwise selection is generally detrimental to statistical estimates.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Statistical estimates always have some uncertainty. Consider a simple example of modeling house prices based solely on their area using linear regression. A prediction from this model wouldn’t reveal the exact value of a house based on its area, because different houses of the same size can have ...
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
A detailed guide on the confusion matrix and performance metrics in machine learning. Learn when to use accuracy, precision, recall, F1-score, and how to fine-tune classification thresholds for real-world impact.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Explore key metrics for evaluating classification and regression models.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
The log-rank test is a key tool in survival analysis, commonly used to compare survival curves between groups in medical research. Learn how it works and how to interpret its results.
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
The log-rank test is a key tool in survival analysis, commonly used to compare survival curves between groups in medical research. Learn how it works and how to interpret its results.
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
Leveraging customer behavior through predictive modeling, the BG/NBD model offers a more accurate approach to demand forecasting in the supply chain compared to traditional time-series models.
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
A comparison between machine learning models and univariate time series models for predicting emergency department visit volumes, focusing on predictive accuracy.
Discover the essential steps of Exploratory Data Analysis (EDA) and how to gain insights from your data before building models.
Discover best practices for creating clear and compelling data visualizations that communicate insights effectively.
Data and communication are intricately linked in modern business. This article explores how to balance data analysis with storytelling, ensuring clear and actionable insights.
Discover best practices for creating clear and compelling data visualizations that communicate insights effectively.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
Polynomial regression is a popular extension of linear regression that models nonlinear relationships between the response and explanatory variables. However, despite its name, polynomial regression remains a form of linear regression, as the response variable is still a linear combination of the...
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
Big data is revolutionizing climate science, enabling more accurate predictions and helping formulate effective mitigation strategies.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
This article discusses Monte Carlo dropout and how it is used to estimate uncertainty in multi-class neural network classification, covering methods such as entropy, variance, and predictive probabilities.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
Discover the significance of heart rate variability (HRV) and how the coefficient of variation (CV) provides a more nuanced view of cardiovascular health.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
This article explores the use of K-means clustering in crime analysis, including practical implementation, case studies, and future directions.
A detailed guide on the confusion matrix and performance metrics in machine learning. Learn when to use accuracy, precision, recall, F1-score, and how to fine-tune classification thresholds for real-world impact.
Explore key metrics for evaluating classification and regression models.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
Explore the Granger causality test, a vital tool for determining causal relationships in time-series data across various domains, including economics, climate science, and finance.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
Explore Bayesian A/B testing as a powerful framework for analyzing conversion rates, providing more nuanced insights than traditional frequentist approaches.
Explore the critical role of Bayesian state space models in macroeconometric analysis, with a focus on linear Gaussian models, dimension reduction, and non-linear or non-Gaussian extensions.
Explore Bayesian A/B testing as a powerful framework for analyzing conversion rates, providing more nuanced insights than traditional frequentist approaches.
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
Machine learning (ML) model monitoring is a critical aspect of maintaining the performance and reliability of models in production environments. As organizations increasingly rely on ML models to drive decision-making and automate processes, ensuring these models remain accurate and effective ove...
Degrees of Freedom (DF) are a fundamental concept in statistics, referring to the number of independent values that can vary in an analysis without breaking any constraints. Understanding DF is crucial for accurate statistical testing and data analysis. This concept extends beyond statistics, pla...
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
Discover incremental learning in time series forecasting, a technique that dynamically updates models with new data for better accuracy and efficiency.
Explore how graph theory is applied to optimize production systems and supply chains. Learn how network optimization and resource allocation techniques improve efficiency and streamline operations.
Learn how graph theory is applied to network analysis in production systems to optimize processes, identify bottlenecks, and improve supply chain efficiency.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Explore entropy’s role in thermodynamics, information theory, and quantum mechanics, and its broader implications in physics and beyond.
Introduction
Learn how IoT-enabled sensors like vibration, temperature, and pressure sensors gather crucial data for predictive maintenance, allowing for real-time monitoring and more effective maintenance strategies.
Simpson’s Paradox shows how aggregated data can lead to misleading trends. Learn the theory behind this paradox, its practical implications, and how to analyze data rigorously.
This article explores the complex interplay between traffic control, pedestrian movement, and the application of fluid dynamics to model and manage these phenomena in urban environments.
Dive into the fascinating world of pedestrian behavior through mathematical models like the Social Force Model. Learn how these models inform urban planning, crowd management, and traffic control for safer and more efficient public spaces.
This article explores the complex interplay between traffic control, pedestrian movement, and the application of fluid dynamics to model and manage these phenomena in urban environments.
Dive into the fascinating world of pedestrian behavior through mathematical models like the Social Force Model. Learn how these models inform urban planning, crowd management, and traffic control for safer and more efficient public spaces.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Maryam Mirzakhani made history as the first woman to win the Fields Medal for her groundbreaking work on the geometry of Riemann surfaces. Her contributions continue to inspire mathematicians today.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
A detailed exploration of Customer Lifetime Value (CLV) for data practitioners and marketers, including its calculation, prediction, and integration with other business data.
Sunrise in Lisbon Harbour, December 2020
Dive into Gaussian Processes for time-series analysis using Python, combining flexible modeling with Bayesian inference for trends, seasonality, and noise.
Introduction
An in-depth exploration of how the closure of open-source data platforms threatens the growth of Large Language Models and the vital role humans play in this ecosystem.
Explore the diverse applications of rolling windows in signal processing, covering both the underlying theory and practical implementations.
runner Package
Explore the runner package in R, which allows applying any R function to rolling windows of data with full control over window size, lags, and index types.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Regression and path analysis are two statistical techniques used to model relationships between variables. This article explains their differences, highlighting key features and use cases for each.
Regression and path analysis are two statistical techniques used to model relationships between variables. This article explains their differences, highlighting key features and use cases for each.
1. Introduction
Learn the core concepts of binary classification, explore common algorithms like Decision Trees and SVMs, and discover how to evaluate performance using precision, recall, and F1-score.
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Explore the diverse applications of rolling windows in signal processing, covering both the underlying theory and practical implementations.
Stepwise Regression
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
Learn about sequential detection techniques for identifying switches in models with changing structures. Explore methods for detecting structural changes in time-series data and dynamic systems.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Sunrise in Lisbon Harbour, December 2020
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
AI and machine learning are transforming renewable energy systems, making them more efficient, reliable, and sustainable. Learn how intelligent technologies are powering the clean energy transition.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
AI and machine learning are transforming renewable energy systems, making them more efficient, reliable, and sustainable. Learn how intelligent technologies are powering the clean energy transition.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
This article explores the fundamentals of data engineering, including the ETL/ELT processes, required skills, and the relationship with data science.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
A comprehensive guide to spectral clustering and its role in dimensionality reduction, enhancing data analysis, and uncovering patterns in machine learning.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
As AI revolutionizes elderly care, ethical concerns around privacy, autonomy, and consent come into focus. This article explores how to balance technological advancements with the dignity and personal preferences of elderly individuals.
Learn about sequential detection techniques for identifying switches in models with changing structures. Explore methods for detecting structural changes in time-series data and dynamic systems.
Sequential change-point detection plays a crucial role in real-time monitoring across industries. Learn about advanced methods, their practical applications, and how they help detect changes in univariate models.
Learn about sequential detection techniques for identifying switches in models with changing structures. Explore methods for detecting structural changes in time-series data and dynamic systems.
Sequential change-point detection plays a crucial role in real-time monitoring across industries. Learn about advanced methods, their practical applications, and how they help detect changes in univariate models.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Exploring Climate Value at Risk (VaR) from a data science perspective, detailing its role in assessing financial risks associated with climate change.
COPOD is a popular anomaly detection model, but how well does it perform in practice? This article discusses critical validation issues in third-party models and lessons learned from COPOD.
Discover critical lessons learned from validating COPOD, a popular anomaly detection model, through test-driven validation techniques. Avoid common pitfalls in anomaly detection modeling.
Discover the importance of feature engineering in enhancing machine learning models. Learn essential techniques for transforming raw data into valuable inputs that drive better predictive performance.
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
A deep dive into using Genetic Algorithms to create more accurate, interpretable decision trees for classification tasks.
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Explore the challenges of using traditional hypothesis testing for detecting data drift in machine learning models and learn how Bayesian probability offers a more robust alternative for monitoring data shifts.
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
Introduction
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
Introduction
Abstract
Introduction
Learn the essential concepts of statistical significance and how it applies to data analysis and business decision-making.
Introduction
Basics of the Logrank Test
Hyperparameter tuning can drastically improve model performance. Explore common search strategies and tools.
Stepwise Regression
Explore the differences between ROC AUC and Precision-Recall AUC in machine learning and learn when to use each metric for classification tasks.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Outliers, or extreme observations in datasets, can have a significant impact on statistical analysis. Learn how to detect, analyze, and manage outliers effectively to ensure robust data analysis.
Outliers are data points that significantly deviate from the rest of the observations in a dataset. They can arise from various sources such as measurement errors, data entry mistakes, or inherent variability in the data. While outliers can provide valuable insights, they can also distort statist...
Introduction
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Introduction
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Absorption and Reflection
There is a clear reason why stepwise regression is usually inappropriate, along with several other significant drawbacks. This article will delve into these issues, providing an in-depth understanding of why stepwise selection is generally detrimental to statistical estimates.
Introduction
Multicollinearity is a common issue in regression analysis. Learn about its implications, misconceptions, and techniques to manage it in statistical modeling.
Introduction
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Moving averages are a cornerstone of stock trading, renowned for their ability to illuminate price trends by filtering out short-term volatility. But the utility of moving averages extends far beyond the financial markets. When applied to the analysis of individual behavior, moving averages offer...
Statistical estimates always have some uncertainty. Consider a simple example of modeling house prices based solely on their area using linear regression. A prediction from this model wouldn’t reveal the exact value of a house based on its area, because different houses of the same size can have ...
Non-intrusive load monitoring (NILM) is an advanced technique that disaggregates a building’s total energy consumption into the usage patterns of individual appliances, all without requiring hardware installation on each device. This approach not only offers a cost-effective and scalable solution...
Non-intrusive load monitoring (NILM) is a technique for monitoring energy consumption in buildings without the need for hardware installation on individual appliances. This makes it a cost-effective and scalable solution for increasing energy efficiency and lowering energy consumption. This artic...
Non-intrusive load monitoring (NILM) is an advanced technique that disaggregates a building’s total energy consumption into the usage patterns of individual appliances, all without requiring hardware installation on each device. This approach not only offers a cost-effective and scalable solution...
Non-intrusive load monitoring (NILM) is a technique for monitoring energy consumption in buildings without the need for hardware installation on individual appliances. This makes it a cost-effective and scalable solution for increasing energy efficiency and lowering energy consumption. This artic...
Non-intrusive load monitoring (NILM) is an advanced technique that disaggregates a building’s total energy consumption into the usage patterns of individual appliances, all without requiring hardware installation on each device. This approach not only offers a cost-effective and scalable solution...
Non-intrusive load monitoring (NILM) is a technique for monitoring energy consumption in buildings without the need for hardware installation on individual appliances. This makes it a cost-effective and scalable solution for increasing energy efficiency and lowering energy consumption. This artic...
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
Sequential detection of structural changes in models is a critical aspect in various domains, enabling timely and informed decision-making. This involves identifying moments when the parameters or structure of a model change, often signaling significant events or shifts in the underlying data-gen...
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Introducing ikNN: An Interpretable k Nearest Neighbors Model
Data drift is one of the primary threats to model reliability in production. This article walks through how to detect it using both statistical techniques and modern monitoring tools.
Machine learning models are trained with historical data, but once they are used in the real world, they may become outdated and lose their accuracy over time due to a phenomenon called drift. Drift is the change over time in the statistical properties of the data that was used to train a machine...
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
Explore how Python and machine learning can be applied to analyze and improve building energy efficiency. Learn key techniques for assessing sustainability, optimizing energy usage, and reducing carbon footprints.
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Explore how Python and machine learning can be applied to analyze and improve building energy efficiency. Learn key techniques for assessing sustainability, optimizing energy usage, and reducing carbon footprints.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Fundamental research is often targeted for cuts due to its lack of immediate outcomes. But eliminating it risks innovation, education, crisis response, and global competitiveness.
Explore how mathematics shapes modern society across fields like technology, education, and problem-solving. This article delves into the often overlooked impact of mathematics on innovation and societal progress.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Explore adaptive performance estimation techniques in machine learning, including methods like CBPE and PAPE. Learn how these approaches help monitor model performance and detect issues like data drift and covariate shift.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Explore how graph theory is applied to optimize production systems and supply chains. Learn how network optimization and resource allocation techniques improve efficiency and streamline operations.
Learn how to manage covariate shifts in machine learning models through effective model monitoring, feature engineering, and adaptation strategies to maintain model accuracy and performance.
Explore the challenges of using traditional hypothesis testing for detecting data drift in machine learning models and learn how Bayesian probability offers a more robust alternative for monitoring data shifts.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
Learn about sequential detection techniques for identifying switches in models with changing structures. Explore methods for detecting structural changes in time-series data and dynamic systems.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Predictive analytics in healthcare is transforming how providers foresee health problems using machine learning and patient data. This article discusses key use cases such as hospital readmissions and chronic disease management.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
A data-driven business strategy integrates Business Intelligence and Data Science to drive informed decisions, optimize resources, and stay competitive.
The fusion of Business Intelligence and Machine Learning offers a pathway from historical analysis to predictive and prescriptive decision-making.
Deploying machine learning models to production requires planning and robust infrastructure. Here are key practices to ensure success.
This checklist helps Data Science professionals ensure thorough validation of their projects before declaring success and deploying models.
Discover the essential steps of Exploratory Data Analysis (EDA) and how to gain insights from your data before building models.
Explore how to perform effective Exploratory Data Analysis (EDA) using Pandas, a powerful Python library. Learn data loading, cleaning, visualization, and advanced EDA techniques.
Explore time-series classification in Python with step-by-step examples using simple models, the catch22 feature set, and UEA/UCR repository benchmarking with statistical tests.
Explore how simple distributional models for time-series classification can be extended with additional feature sets like catch22 to improve performance without sacrificing interpretability.
Neural networks power many modern AI applications. This article introduces their basic structure and training process.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Data science is revolutionizing chronic disease management among the elderly by leveraging predictive analytics to monitor disease progression, manage medications, and create personalized treatment plans.
Machine learning is revolutionizing medical diagnosis by providing faster, more accurate tools for detecting diseases such as cancer, heart disease, and neurological disorders.
Machine learning is revolutionizing fall prevention in elderly care by predicting the likelihood of falls through wearable sensor data, mobility analysis, and health history insights.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Machine learning is revolutionizing fall prevention in elderly care by predicting the likelihood of falls through wearable sensor data, mobility analysis, and health history insights.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
The integration of IoT and big data is revolutionizing elderly care by enabling remote monitoring systems that track vital signs, detect emergencies, and ensure quick responses to health risks.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Explore the critical role of Bayesian state space models in macroeconometric analysis, with a focus on linear Gaussian models, dimension reduction, and non-linear or non-Gaussian extensions.
Dynamic systems theory helps economists analyze the evolution of economic variables over time, focusing on stability and equilibrium.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
Differential equations are essential in modeling economic growth, providing insight into long-term trends and the impact of policy changes on macroeconomic variables.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
Explore the critical role of Bayesian state space models in macroeconometric analysis, with a focus on linear Gaussian models, dimension reduction, and non-linear or non-Gaussian extensions.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
Multi-agent systems are redefining how financial tasks like M&A analysis can be approached, using teams of collaborative LLMs with distinct responsibilities.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
Multi-agent systems are redefining how financial tasks like M&A analysis can be approached, using teams of collaborative LLMs with distinct responsibilities.
Explore the evolution of probability calibration methods in machine learning, from histogram binning to Venn–ABERS predictors, with a deep dive into theory, implementation, and applications.
Why the intuitive idea of regression confidence bands breaks down under mathematical scrutiny.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Predictive maintenance is redefining how industries manage assets, reducing downtime and costs through intelligent monitoring and data-driven decisions.
Data drift is one of the primary threats to model reliability in production. This article walks through how to detect it using both statistical techniques and modern monitoring tools.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Learn the critical difference between correlation and causation in data analysis, how to interpret correlation coefficients, and why controlled experiments are essential for establishing causality.
Dive into the intricacies of describing distributions, understand the mathematics behind common distributions, and see their applications in parametric statistics across multiple disciplines.
Dive into the intricacies of describing distributions, understand the mathematics behind common distributions, and see their applications in parametric statistics across multiple disciplines.
John Nash revolutionized game theory with his Nash equilibrium concept and won the Nobel Prize in Economics. He also faced a lifelong struggle with schizophrenia, making his life a story of genius, triumph, and resilience.
John Nash revolutionized game theory with his Nash equilibrium concept and won the Nobel Prize in Economics. He also faced a lifelong struggle with schizophrenia, making his life a story of genius, triumph, and resilience.
John Nash revolutionized game theory with his Nash equilibrium concept and won the Nobel Prize in Economics. He also faced a lifelong struggle with schizophrenia, making his life a story of genius, triumph, and resilience.
Sophie Germain was a trailblazing mathematician who made groundbreaking contributions to number theory and elasticity. This article explores her life, her challenges, and her lasting impact on mathematics and science.
Sophie Germain was a trailblazing mathematician who made groundbreaking contributions to number theory and elasticity. This article explores her life, her challenges, and her lasting impact on mathematics and science.
Ada Lovelace is celebrated as the first computer programmer for her visionary work on Charles Babbage’s Analytical Engine. Discover her pioneering insights into computational theory, which laid the foundation for modern computing.
Ada Lovelace is celebrated as the first computer programmer for her visionary work on Charles Babbage’s Analytical Engine. Discover her pioneering insights into computational theory, which laid the foundation for modern computing.
Ada Lovelace is celebrated as the first computer programmer for her visionary work on Charles Babbage’s Analytical Engine. Discover her pioneering insights into computational theory, which laid the foundation for modern computing.
David Hilbert, one of the most influential mathematicians of the 20th century, is best known for his ‘Hilbert Problems’ and his pioneering contributions to algebra, geometry, and logic. This article examines his lasting impact on mathematics.
David Hilbert, one of the most influential mathematicians of the 20th century, is best known for his ‘Hilbert Problems’ and his pioneering contributions to algebra, geometry, and logic. This article examines his lasting impact on mathematics.
David Hilbert, one of the most influential mathematicians of the 20th century, is best known for his ‘Hilbert Problems’ and his pioneering contributions to algebra, geometry, and logic. This article examines his lasting impact on mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Kurt Gödel revolutionized the world of mathematical logic with his incompleteness theorems, reshaping our understanding of the limits of formal systems. Learn about his life, work, and lasting legacy in the foundations of mathematics.
Dive into the world of calculus, where derivatives and integrals are used to analyze change and calculate areas under curves. Learn about these fundamental tools and their wide-ranging applications.
Dive into the world of calculus, where derivatives and integrals are used to analyze change and calculate areas under curves. Learn about these fundamental tools and their wide-ranging applications.
Dive into the world of calculus, where derivatives and integrals are used to analyze change and calculate areas under curves. Learn about these fundamental tools and their wide-ranging applications.
Hypatia of Alexandria is recognized as the first known female mathematician. This article explores her contributions to geometry and astronomy, her philosophical influence, and her tragic death.
Hypatia of Alexandria is recognized as the first known female mathematician. This article explores her contributions to geometry and astronomy, her philosophical influence, and her tragic death.
Explore the differences between the Shapiro-Wilk and Anderson-Darling tests, two common methods for testing normality, and how sample size and distribution affect their performance.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
Splines are powerful tools for modeling complex, nonlinear relationships in data. In this article, we’ll explore what splines are, how they work, and how they are used in data analysis, statistics, and machine learning.
AUC-ROC and Gini are popular metrics for evaluating binary classifiers, but they can be misleading on imbalanced datasets. Discover why AUC-PR, with its focus on Precision and Recall, offers a better evaluation for handling rare events.
AUC-ROC and Gini are popular metrics for evaluating binary classifiers, but they can be misleading on imbalanced datasets. Discover why AUC-PR, with its focus on Precision and Recall, offers a better evaluation for handling rare events.
AUC-ROC and Gini are popular metrics for evaluating binary classifiers, but they can be misleading on imbalanced datasets. Discover why AUC-PR, with its focus on Precision and Recall, offers a better evaluation for handling rare events.
AUC-ROC and Gini are popular metrics for evaluating binary classifiers, but they can be misleading on imbalanced datasets. Discover why AUC-PR, with its focus on Precision and Recall, offers a better evaluation for handling rare events.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
This article delves into mathematical models of inequality, focusing on the Lorenz curve and Gini coefficient to measure and interpret economic disparities.
Machine learning models degrade over time due to model drift, which includes data drift, concept drift, and feature drift. Learn how to detect, measure, and mitigate these challenges.
Machine learning models degrade over time due to model drift, which includes data drift, concept drift, and feature drift. Learn how to detect, measure, and mitigate these challenges.
Understand how causal reasoning helps us move beyond correlation, resolving paradoxes and leading to more accurate insights from data analysis.
Understand how causal reasoning helps us move beyond correlation, resolving paradoxes and leading to more accurate insights from data analysis.
Discover the fundamentals of Maximum Likelihood Estimation (MLE), its role in data science, and how it impacts businesses through predictive analytics and risk modeling.
The Kolmogorov-Smirnov test is a powerful tool for assessing goodness-of-fit in non-parametric data. Learn how it works, how it compares to the Shapiro-Wilk test, and explore real-world applications.
The Kolmogorov-Smirnov test is a powerful tool for assessing goodness-of-fit in non-parametric data. Learn how it works, how it compares to the Shapiro-Wilk test, and explore real-world applications.
The Kolmogorov-Smirnov test is a powerful tool for assessing goodness-of-fit in non-parametric data. Learn how it works, how it compares to the Shapiro-Wilk test, and explore real-world applications.
The Kolmogorov-Smirnov test is a powerful tool for assessing goodness-of-fit in non-parametric data. Learn how it works, how it compares to the Shapiro-Wilk test, and explore real-world applications.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
The multiple comparisons problem arises in hypothesis testing when performing multiple tests increases the likelihood of false positives. Learn about the Bonferroni correction and other solutions to control error rates.
One-way and two-way ANOVA are essential tools for comparing means across groups, but each test serves different purposes. Learn when to use one-way versus two-way ANOVA and how to interpret their results.
One-way and two-way ANOVA are essential tools for comparing means across groups, but each test serves different purposes. Learn when to use one-way versus two-way ANOVA and how to interpret their results.
One-way and two-way ANOVA are essential tools for comparing means across groups, but each test serves different purposes. Learn when to use one-way versus two-way ANOVA and how to interpret their results.
One-way and two-way ANOVA are essential tools for comparing means across groups, but each test serves different purposes. Learn when to use one-way versus two-way ANOVA and how to interpret their results.
Machine learning is transforming climate science, offering powerful predictive tools for forecasting extreme weather, rising sea levels, and biodiversity shifts.
Machine learning is transforming climate science, offering powerful predictive tools for forecasting extreme weather, rising sea levels, and biodiversity shifts.
Before applying the Box-Cox transformation, it is crucial to consider its implications on model assumptions, interpretation, and hypothesis testing. This article explores 12 critical questions you should ask yourself before using the transformation.
The Log-Rank test is a vital statistical method used to compare survival curves in clinical studies. This article explores its significance in medical research, including applications in clinical trials and epidemiology.
Time series analysis is a vital tool in epidemiology, allowing researchers to model the spread of diseases, detect outbreaks, and predict future trends in infection rates.
Time series analysis is a vital tool in epidemiology, allowing researchers to model the spread of diseases, detect outbreaks, and predict future trends in infection rates.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Grace Hopper revolutionized computer science by developing the first compiler and contributing to COBOL. Discover her groundbreaking work and her legacy in the field of programming.
Most diagrams for choosing statistical tests miss the bigger picture. Here’s a bold, practical approach that emphasizes interpretation over mechanistic rules, and cuts through statistical misconceptions like the N>30 rule.
Most diagrams for choosing statistical tests miss the bigger picture. Here’s a bold, practical approach that emphasizes interpretation over mechanistic rules, and cuts through statistical misconceptions like the N>30 rule.
Most diagrams for choosing statistical tests miss the bigger picture. Here’s a bold, practical approach that emphasizes interpretation over mechanistic rules, and cuts through statistical misconceptions like the N>30 rule.
Residual diagnostics often trigger debates, especially when tests like Shapiro-Wilk suggest non-normality. But should it be the final verdict on your model? Let’s dive deeper into residual analysis, focusing on its impact in GLS, mixed models, and robust alternatives.
Residual diagnostics often trigger debates, especially when tests like Shapiro-Wilk suggest non-normality. But should it be the final verdict on your model? Let’s dive deeper into residual analysis, focusing on its impact in GLS, mixed models, and robust alternatives.
Residual diagnostics often trigger debates, especially when tests like Shapiro-Wilk suggest non-normality. But should it be the final verdict on your model? Let’s dive deeper into residual analysis, focusing on its impact in GLS, mixed models, and robust alternatives.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
The Cox Proportional Hazards Model is a vital tool for analyzing time-to-event data in medical studies. Learn how it works and its applications in survival analysis.
Learn the key differences between ANOVA and Kruskal-Wallis tests, and understand when to use each method based on your data’s assumptions and characteristics.
The ARIMAX model extends ARIMA by integrating exogenous variables into time series forecasting, offering more accurate predictions for complex systems.
Explore Type I and Type II errors in hypothesis testing. Learn how to balance error rates, interpret significance levels, and understand the implications of statistical errors in real-world scenarios.
Explore Type I and Type II errors in hypothesis testing. Learn how to balance error rates, interpret significance levels, and understand the implications of statistical errors in real-world scenarios.
Real-time data processing platforms like Apache Flink are revolutionizing epidemiological surveillance by providing timely, accurate insights that enable rapid response to disease outbreaks and public health threats.
Real-time data processing platforms like Apache Flink are revolutionizing epidemiological surveillance by providing timely, accurate insights that enable rapid response to disease outbreaks and public health threats.
Real-time data processing platforms like Apache Flink are revolutionizing epidemiological surveillance by providing timely, accurate insights that enable rapid response to disease outbreaks and public health threats.
Real-time data processing platforms like Apache Flink are revolutionizing epidemiological surveillance by providing timely, accurate insights that enable rapid response to disease outbreaks and public health threats.
Real-time data processing platforms like Apache Flink are revolutionizing epidemiological surveillance by providing timely, accurate insights that enable rapid response to disease outbreaks and public health threats.
Data science is a key driver of sustainability, offering insights that help optimize resources, reduce waste, and improve the energy efficiency of supply chains.
Data science is a key driver of sustainability, offering insights that help optimize resources, reduce waste, and improve the energy efficiency of supply chains.
Data science is a key driver of sustainability, offering insights that help optimize resources, reduce waste, and improve the energy efficiency of supply chains.
The Friedman test is a non-parametric alternative to repeated measures ANOVA, designed for use with ordinal data or non-normal distributions. Learn how and when to use it in your analyses.
The Friedman test is a non-parametric alternative to repeated measures ANOVA, designed for use with ordinal data or non-normal distributions. Learn how and when to use it in your analyses.
The Friedman test is a non-parametric alternative to repeated measures ANOVA, designed for use with ordinal data or non-normal distributions. Learn how and when to use it in your analyses.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Learn about different methods for estimating prediction error, addressing the bias-variance tradeoff, and how cross-validation, bootstrap methods, and Efron & Tibshirani’s .632 estimator help improve model evaluation.
Learn what the False Positive Rate (FPR) is, how it impacts machine learning models, and when to use it for better evaluation.
Discover the foundations of Ordinary Least Squares (OLS) regression, its key properties such as consistency, efficiency, and maximum likelihood estimation, and its applications in linear modeling.
Discover the foundations of Ordinary Least Squares (OLS) regression, its key properties such as consistency, efficiency, and maximum likelihood estimation, and its applications in linear modeling.
Discover the foundations of Ordinary Least Squares (OLS) regression, its key properties such as consistency, efficiency, and maximum likelihood estimation, and its applications in linear modeling.
Discover the foundations of Ordinary Least Squares (OLS) regression, its key properties such as consistency, efficiency, and maximum likelihood estimation, and its applications in linear modeling.
Understand Cochran’s Q test, a non-parametric test for comparing proportions across related groups, and its applications in binary data and its connection to McNemar’s test.
Understand Cochran’s Q test, a non-parametric test for comparing proportions across related groups, and its applications in binary data and its connection to McNemar’s test.
The Mann-Whitney U test and independent t-test are used for comparing two independent groups, but the choice between them depends on data distribution. Learn when to use each and explore real-world applications.
The Mann-Whitney U test and independent t-test are used for comparing two independent groups, but the choice between them depends on data distribution. Learn when to use each and explore real-world applications.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
Explore the different types of observational errors, their causes, and their impact on accuracy and precision in various fields, such as data science and engineering.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
A guide to solving DSGE models numerically, focusing on perturbation techniques and finite difference methods used in economic modeling.
This article delves into the fundamentals of Markov Chain Monte Carlo (MCMC), its applications, and its significance in solving complex, high-dimensional probability distributions.
This article explores the use of stationary distributions in time series models to define thresholds in zero-inflated data, improving classification accuracy.
This article explores the use of stationary distributions in time series models to define thresholds in zero-inflated data, improving classification accuracy.
The log-rank test is a key tool in survival analysis, commonly used to compare survival curves between groups in medical research. Learn how it works and how to interpret its results.
Leveraging customer behavior through predictive modeling, the BG/NBD model offers a more accurate approach to demand forecasting in the supply chain compared to traditional time-series models.
Leveraging customer behavior through predictive modeling, the BG/NBD model offers a more accurate approach to demand forecasting in the supply chain compared to traditional time-series models.
A comparison between machine learning models and univariate time series models for predicting emergency department visit volumes, focusing on predictive accuracy.
A comparison between machine learning models and univariate time series models for predicting emergency department visit volumes, focusing on predictive accuracy.
Explore the fundamentals of Bayesian inference and how prior beliefs combine with data to form posterior conclusions.
See how hypothesis testing helps draw meaningful conclusions from data in practical scenarios.
Learn how data science revolutionizes predictive maintenance through key techniques like regression, anomaly detection, and clustering to forecast machine failures and optimize maintenance schedules.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Katherine Johnson was a trailblazing mathematician at NASA whose calculations for the Mercury and Apollo missions helped guide U.S. space exploration. Learn about her groundbreaking contributions to applied mathematics.
Explore the architecture of ordinal regression models, their applications in real-world data, and how marginal effects enhance the interpretability of complex models using Python.
Explore the architecture of ordinal regression models, their applications in real-world data, and how marginal effects enhance the interpretability of complex models using Python.
PDEs offer a powerful framework for understanding complex systems in fields like physics, finance, and environmental science. Discover how data scientists can integrate PDEs with modern machine learning techniques to create robust predictive models.
PDEs offer a powerful framework for understanding complex systems in fields like physics, finance, and environmental science. Discover how data scientists can integrate PDEs with modern machine learning techniques to create robust predictive models.
Julia Robinson was a trailblazing mathematician known for her work on decision problems and number theory. She played a crucial role in solving Hilbert’s Tenth Problem and became the first woman elected to the National Academy of Sciences.
Julia Robinson was a trailblazing mathematician known for her work on decision problems and number theory. She played a crucial role in solving Hilbert’s Tenth Problem and became the first woman elected to the National Academy of Sciences.
Julia Robinson was a trailblazing mathematician known for her work on decision problems and number theory. She played a crucial role in solving Hilbert’s Tenth Problem and became the first woman elected to the National Academy of Sciences.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
A deep dive into using Kernel Density Estimation (KDE) for identifying traffic accident hotspots and improving road safety, including practical applications and case studies from Japan.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
Discover the reasons behind asymmetric confidence intervals in statistics and how they impact research interpretation.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
A study using GIS-based techniques for forest fire hotspot identification and analysis, validated with contributory factors like population density, precipitation, elevation, and vegetation cover.
Big data is revolutionizing climate science, enabling more accurate predictions and helping formulate effective mitigation strategies.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
Rare labels in categorical variables can cause significant issues in machine learning, such as overfitting. This article explains why rare labels can be problematic and provides examples on how to handle them.
This article discusses Monte Carlo dropout and how it is used to estimate uncertainty in multi-class neural network classification, covering methods such as entropy, variance, and predictive probabilities.
This article discusses Monte Carlo dropout and how it is used to estimate uncertainty in multi-class neural network classification, covering methods such as entropy, variance, and predictive probabilities.
Explore the differences between classical statistical models and machine learning algorithms in predictive maintenance, including their performance, accuracy, and scalability in industrial settings.
Discover the significance of heart rate variability (HRV) and how the coefficient of variation (CV) provides a more nuanced view of cardiovascular health.
Discover the significance of heart rate variability (HRV) and how the coefficient of variation (CV) provides a more nuanced view of cardiovascular health.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
Explore the foundations, concepts, and mathematics behind Kernel Density Estimation (KDE), a powerful tool in non-parametric statistics for estimating probability density functions.
RFM Segmentation (Recency, Frequency, Monetary Value) is a widely used method to segment customers based on their behavior. This article provides a deep dive into RFM, showing how to apply clustering techniques for effective customer segmentation.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
Regression tasks are at the heart of machine learning. This guide explores methods like Linear Regression, Principal Component Regression, Gaussian Process Regression, and Support Vector Regression, with insights on when to use each.
A step-by-step guide to implementing Linear Regression from scratch using the Normal Equation method, complete with Python code and evaluation techniques.
This article explores the use of K-means clustering in crime analysis, including practical implementation, case studies, and future directions.
This article explores the use of K-means clustering in crime analysis, including practical implementation, case studies, and future directions.
Explore key metrics for evaluating classification and regression models.
Linear Programming is the foundation of optimization in operations research. We explore its traditional methods, challenges in scaling large instances, and introduce PDLP, a scalable solver using first-order methods, designed for modern computational infrastructures.
Linear Programming is the foundation of optimization in operations research. We explore its traditional methods, challenges in scaling large instances, and introduce PDLP, a scalable solver using first-order methods, designed for modern computational infrastructures.
Linear Programming is the foundation of optimization in operations research. We explore its traditional methods, challenges in scaling large instances, and introduce PDLP, a scalable solver using first-order methods, designed for modern computational infrastructures.
Linear Programming is the foundation of optimization in operations research. We explore its traditional methods, challenges in scaling large instances, and introduce PDLP, a scalable solver using first-order methods, designed for modern computational infrastructures.
Discover how data science enhances supply chain optimization and industrial network analysis, leveraging techniques like predictive analytics, machine learning, and graph theory to optimize operations.
Discover how data science enhances supply chain optimization and industrial network analysis, leveraging techniques like predictive analytics, machine learning, and graph theory to optimize operations.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore how Finite Difference Methods and the Black-Scholes-Merton differential equation are used to solve option pricing problems numerically, with a focus on explicit and implicit schemes.
Explore exchange rate models like Purchasing Power Parity (PPP) and Uncovered Interest Parity (UIP), key frameworks in global economics.
Explore exchange rate models like Purchasing Power Parity (PPP) and Uncovered Interest Parity (UIP), key frameworks in global economics.
Explore exchange rate models like Purchasing Power Parity (PPP) and Uncovered Interest Parity (UIP), key frameworks in global economics.
A deep dive into the relationship between OLS and Theil-Sen estimators, revealing their connection through weighted averages and robust median-based slopes.
A deep dive into the relationship between OLS and Theil-Sen estimators, revealing their connection through weighted averages and robust median-based slopes.
A deep dive into the relationship between OLS and Theil-Sen estimators, revealing their connection through weighted averages and robust median-based slopes.
A deep dive into the relationship between OLS and Theil-Sen estimators, revealing their connection through weighted averages and robust median-based slopes.
Explore the Granger causality test, a vital tool for determining causal relationships in time-series data across various domains, including economics, climate science, and finance.
Explore the Granger causality test, a vital tool for determining causal relationships in time-series data across various domains, including economics, climate science, and finance.
Discover how linear programming and Python’s PuLP library can efficiently solve staff scheduling challenges, minimizing costs while meeting operational demands.
Levene’s Test and Bartlett’s Test are key tools for checking homogeneity of variances in data. Learn when to use each test, based on normality assumptions, and how they relate to tests like ANOVA.
Levene’s Test and Bartlett’s Test are key tools for checking homogeneity of variances in data. Learn when to use each test, based on normality assumptions, and how they relate to tests like ANOVA.
Levene’s Test and Bartlett’s Test are key tools for checking homogeneity of variances in data. Learn when to use each test, based on normality assumptions, and how they relate to tests like ANOVA.
Levene’s Test and Bartlett’s Test are key tools for checking homogeneity of variances in data. Learn when to use each test, based on normality assumptions, and how they relate to tests like ANOVA.
Discover incremental learning in time series forecasting, a technique that dynamically updates models with new data for better accuracy and efficiency.
Discover incremental learning in time series forecasting, a technique that dynamically updates models with new data for better accuracy and efficiency.
Discover incremental learning in time series forecasting, a technique that dynamically updates models with new data for better accuracy and efficiency.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
Dorothy Vaughan was a pioneering mathematician and computer scientist who led NASA’s computing division and became a leader in FORTRAN programming. She overcame racial and gender barriers to contribute to the U.S. space program.
Spatial epidemiology combines geospatial data with data science techniques to track and analyze disease outbreaks, offering public health agencies critical tools for intervention and planning.
Spatial epidemiology combines geospatial data with data science techniques to track and analyze disease outbreaks, offering public health agencies critical tools for intervention and planning.
Spatial epidemiology combines geospatial data with data science techniques to track and analyze disease outbreaks, offering public health agencies critical tools for intervention and planning.
Spatial epidemiology combines geospatial data with data science techniques to track and analyze disease outbreaks, offering public health agencies critical tools for intervention and planning.
Explore the Wald test, a key tool in hypothesis testing for regression models, its applications, and its role in logistic regression, Poisson regression, and beyond.
Explore the Wald test, a key tool in hypothesis testing for regression models, its applications, and its role in logistic regression, Poisson regression, and beyond.
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
In machine learning, linear models assume a direct relationship between predictors and outcome variables. Learn why understanding these assumptions is critical for model performance and how to work with non-linear relationships.
Learn how IoT-enabled sensors like vibration, temperature, and pressure sensors gather crucial data for predictive maintenance, allowing for real-time monitoring and more effective maintenance strategies.
Explore the jackknife technique, a robust resampling method used in statistics for estimating bias, variance, and confidence intervals, with applications across various fields.
Explore the jackknife technique, a robust resampling method used in statistics for estimating bias, variance, and confidence intervals, with applications across various fields.
Delve into bootstrapping, a versatile statistical technique for estimating the sampling distribution of a statistic, offering insights into its applications and implementation.
Delve into bootstrapping, a versatile statistical technique for estimating the sampling distribution of a statistic, offering insights into its applications and implementation.
Simpson’s Paradox shows how aggregated data can lead to misleading trends. Learn the theory behind this paradox, its practical implications, and how to analyze data rigorously.
Simpson’s Paradox shows how aggregated data can lead to misleading trends. Learn the theory behind this paradox, its practical implications, and how to analyze data rigorously.
Delve into how multiple linear regression and binary logistic regression handle errors. Learn about explicit and implicit error terms and their impact on model performance.
Delve into how multiple linear regression and binary logistic regression handle errors. Learn about explicit and implicit error terms and their impact on model performance.
Delve into how multiple linear regression and binary logistic regression handle errors. Learn about explicit and implicit error terms and their impact on model performance.
Dive into the fascinating world of pedestrian behavior through mathematical models like the Social Force Model. Learn how these models inform urban planning, crowd management, and traffic control for safer and more efficient public spaces.
Dive into the fascinating world of pedestrian behavior through mathematical models like the Social Force Model. Learn how these models inform urban planning, crowd management, and traffic control for safer and more efficient public spaces.
An in-depth exploration of sequential testing and its application in A/B testing. Understand the statistical underpinnings, advantages, limitations, and practical implementations in R, JavaScript, and Python.
The Chi-Square Test is a powerful tool for analyzing relationships in categorical data. Learn its principles and practical applications.
Explore the key concepts of Mean Time Between Failures (MTBF), how it is calculated, its applications, and its alternatives in system reliability.
Explore the key concepts of Mean Time Between Failures (MTBF), how it is calculated, its applications, and its alternatives in system reliability.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
The Fowlkes-Mallows Index is a statistical measure used for evaluating clustering and classification performance by comparing the similarity of data groupings.
A detailed exploration of Value at Risk (VaR), covering its different types, methods of calculation, and applications in modern portfolio management.
Maryam Mirzakhani made history as the first woman to win the Fields Medal for her groundbreaking work on the geometry of Riemann surfaces. Her contributions continue to inspire mathematicians today.
Maryam Mirzakhani made history as the first woman to win the Fields Medal for her groundbreaking work on the geometry of Riemann surfaces. Her contributions continue to inspire mathematicians today.
Maryam Mirzakhani made history as the first woman to win the Fields Medal for her groundbreaking work on the geometry of Riemann surfaces. Her contributions continue to inspire mathematicians today.
A detailed exploration of Customer Lifetime Value (CLV) for data practitioners and marketers, including its calculation, prediction, and integration with other business data.
Dive into Gaussian Processes for time-series analysis using Python, combining flexible modeling with Bayesian inference for trends, seasonality, and noise.
SNN is a distance metric that enhances traditional methods like k Nearest Neighbors, especially in high-dimensional, variable-density datasets.
Discover how data science, a multidisciplinary field combining statistics, computer science, and domain expertise, can drive better business decisions and outcomes.
An in-depth exploration of how the closure of open-source data platforms threatens the growth of Large Language Models and the vital role humans play in this ecosystem.
An in-depth exploration of how the closure of open-source data platforms threatens the growth of Large Language Models and the vital role humans play in this ecosystem.
Delve into the fascinating life of Paul Erdős, a wandering mathematician whose love for numbers and collaboration reshaped the world of mathematics.
Delve into the fascinating life of Paul Erdős, a wandering mathematician whose love for numbers and collaboration reshaped the world of mathematics.
Delve into the fascinating life of Paul Erdős, a wandering mathematician whose love for numbers and collaboration reshaped the world of mathematics.
Learn the key differences between MANOVA and ANOVA, and when to apply them in experimental designs with multiple dependent variables, such as clinical trials.
Learn the key differences between MANOVA and ANOVA, and when to apply them in experimental designs with multiple dependent variables, such as clinical trials.
Learn the key differences between MANOVA and ANOVA, and when to apply them in experimental designs with multiple dependent variables, such as clinical trials.
runner Package
Explore the runner package in R, which allows applying any R function to rolling windows of data with full control over window size, lags, and index types.
This article explores the complex interplay between traffic control, pedestrian movement, and the application of fluid dynamics to model and manage these phenomena in urban environments.
This article explores the complex interplay between traffic control, pedestrian movement, and the application of fluid dynamics to model and manage these phenomena in urban environments.
Explore the diverse applications of rolling windows in signal processing, covering both the underlying theory and practical implementations.
Explore the diverse applications of rolling windows in signal processing, covering both the underlying theory and practical implementations.
Innumeracy is becoming the new illiteracy, with far-reaching implications for decision-making in various aspects of life. Discover how the inability to understand numbers affects our world and what can be done to address this growing issue.
Innumeracy is becoming the new illiteracy, with far-reaching implications for decision-making in various aspects of life. Discover how the inability to understand numbers affects our world and what can be done to address this growing issue.
Data and communication are intricately linked in modern business. This article explores how to balance data analysis with storytelling, ensuring clear and actionable insights.
Dive into the nuances of sample size in statistical analysis, challenging the common belief that larger samples always lead to better results.
Learn the differences between multiple regression and stepwise regression, and discover when to use each method to build the best predictive models in business analytics and scientific research.
Understanding coverage probability in statistical estimation and prediction: its role in constructing confidence intervals and assessing their accuracy.
Understanding coverage probability in statistical estimation and prediction: its role in constructing confidence intervals and assessing their accuracy.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Natural Language Processing (NLP) is integral to data science, enabling tasks like text classification and sentiment analysis. Learn how NLP works, its common tasks, tools, and applications in real-world projects.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Learn how the Mann-Kendall Test is used for trend detection in time-series data, particularly in fields like environmental studies, hydrology, and climate research.
Both linear and logistic models offer unique advantages depending on the circumstances. Learn when each model is appropriate and how to interpret their results.
Both linear and logistic models offer unique advantages depending on the circumstances. Learn when each model is appropriate and how to interpret their results.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn the differences between biserial and point-biserial correlation methods, and discover how they can be applied to analyze relationships between continuous and binary variables in educational testing, psychology, and medical diagnostics.
Learn how the Mann-Whitney U Test is used to compare two independent samples in non-parametric statistics, with applications in fields such as psychology, medicine, and ecology.
While engineering projects have defined solutions and known processes, data science is all about experimentation and discovery. Managing them in the same way can be detrimental.
While engineering projects have defined solutions and known processes, data science is all about experimentation and discovery. Managing them in the same way can be detrimental.
While engineering projects have defined solutions and known processes, data science is all about experimentation and discovery. Managing them in the same way can be detrimental.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
Discover how artificial intelligence and machine learning are solving the most pressing challenges in renewable energy through forecasting, grid intelligence, and energy storage optimization.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This in-depth analysis explores how data science is driving measurable carbon reductions across industries through predictive modeling, optimization algorithms, and real-time emissions tracking.
This article explores the fundamentals of data engineering, including the ETL/ELT processes, required skills, and the relationship with data science.
This article explores the fundamentals of data engineering, including the ETL/ELT processes, required skills, and the relationship with data science.
A comprehensive comparison of Value at Risk (VaR) and Expected Shortfall (ES) in financial risk management, with a focus on their performance during volatile and stable market conditions.
A comprehensive comparison of Value at Risk (VaR) and Expected Shortfall (ES) in financial risk management, with a focus on their performance during volatile and stable market conditions.
A comprehensive comparison of Value at Risk (VaR) and Expected Shortfall (ES) in financial risk management, with a focus on their performance during volatile and stable market conditions.
This article delves into the core mathematical principles behind machine learning, including classification and regression settings, loss functions, risk minimization, decision trees, and more.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Text preprocessing is a crucial step in NLP for transforming raw text into a structured format. Learn key techniques like tokenization, stemming, lemmatization, and text normalization for successful NLP tasks.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Marina Viazovska won the Fields Medal in 2022 for her remarkable solution to the sphere packing problem in 8 dimensions and her contributions to Fourier analysis and modular forms.
Discover the significance of the Normal Distribution, also known as the Bell Curve, in statistics and its widespread application in real-world scenarios.
Explore Markov Chain Monte Carlo (MCMC) methods, specifically the Metropolis algorithm, and learn how to perform Bayesian inference through Python code.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Discover how Bayesian inference and MCMC algorithms like Metropolis-Hastings can solve complex probability problems through real-world examples and Python implementation.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Discover the importance of Customer Lifetime Value (CLV) in shaping business strategies, improving customer retention, and enhancing marketing efforts for sustainable growth.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Dive into Topological Data Analysis (TDA) and discover how its methods, such as persistent homology and the mapper algorithm, help uncover hidden insights in high-dimensional and complex datasets.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
Discover the inner workings of clustering algorithms, from K-Means to Spectral Clustering, and how they unveil patterns in machine learning, bioinformatics, and data analysis.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
A journey into the Pigeonhole Principle, uncovering its profound simplicity and exploring its applications in fields like combinatorics, number theory, and geometry.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
An in-depth look into ergodicity and its applications in statistical analysis, mathematical modeling, and computational physics, featuring real-world processes and Python simulations.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
A practical guide to mastering combinatorics with Python, featuring hands-on examples using the itertools library and insights into scientific computing and probability theory.
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
Dive into the intersection of combinatorics and probability, exploring how these fields work together to solve problems in mathematics, data science, and beyond.
As AI revolutionizes elderly care, ethical concerns around privacy, autonomy, and consent come into focus. This article explores how to balance technological advancements with the dignity and personal preferences of elderly individuals.
As AI revolutionizes elderly care, ethical concerns around privacy, autonomy, and consent come into focus. This article explores how to balance technological advancements with the dignity and personal preferences of elderly individuals.
Sequential change-point detection plays a crucial role in real-time monitoring across industries. Learn about advanced methods, their practical applications, and how they help detect changes in univariate models.
The History of Artificial Intelligence
The History of Artificial Intelligence
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
Clustering is one of the most fundamental techniques in data analysis and machine learning. It involves grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other groups. This is widely used across various fields...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
In data analysis and machine learning, the challenge of making sense of large volumes of high-dimensional data is ever-present. Dimensionality reduction, a critical technique in data science, addresses this challenge by simplifying complex datasets into more manageable and interpretable forms wit...
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Abstract
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
Explore the role of survival analysis in management, focusing on time-to-event data and techniques like the Kaplan-Meier estimator and Cox proportional hazards model for business decision-making.
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In mathematics, the concept of “distance” extends beyond the everyday understanding of the term. Typically, when we think of distance, we envision Euclidean distance, which is the straight-line distance between two points in space. This form of distance is familiar and intuitive, often represente...
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
In statistics, the P Value is a fundamental concept that plays a crucial role in hypothesis testing. It quantifies the probability of observing a test statistic at least as extreme as the one observed, assuming the null hypothesis is true. Essentially, the P Value helps us assess whether the obse...
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
Feature engineering is a critical step in the machine learning pipeline, involving the creation, transformation, and selection of variables (features) that can enhance the predictive performance of models. This process requires deep domain knowledge and creativity to extract meaningful informatio...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
In machine learning, ensuring the ongoing accuracy and reliability of models in production is paramount. One significant challenge faced by data scientists and engineers is data drift, where the statistical properties of the input data change over time, leading to potential degradation in model p...
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Dive into Bhattacharyya distance, loss functions such as MSE and cross-entropy, and their applications in optimizing machine learning models for classification and regression.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Learn about the Normalized Gini Coefficient and Default Rate, two essential metrics in credit scoring and risk assessment. Explore their significance in evaluating credit risk and loan defaults.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
Discover the difference between probability and odds in biostatistics, and how these concepts apply to data science and machine learning. A clear explanation of event occurrence and likelihood.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
An in-depth guide to understanding and applying the Probability Integral Transform in various fields, from finance to statistics.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Master the process of writing a research paper with tips on developing a thesis, structuring arguments, organizing literature reviews, and improving academic writing.
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
Learn the key differences between the G-Test and Chi-Square Test for analyzing categorical data, and discover their applications in fields like genetics, market research, and large datasets.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
In this article, we will explore how to model count events, such as activations of certain types of events, using the Poisson distribution in R. We will also discuss how to determine if an observed count belongs to the Poisson distribution.
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
Understanding the z-score can significantly enhance your data analysis skills. Here’s a quick guide to what z-scores are and why they matter:
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
IoT and data science together offer powerful tools for monitoring environmental conditions, analyzing climate data, and supporting global climate action initiatives.
Stepwise Regression
Stepwise Regression
Stepwise Regression
Stepwise Regression
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Dive deep into Matthew’s Correlation Coefficient (MCC), a powerful metric for evaluating binary classification models, especially in imbalanced datasets.
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Electromagnetic interference (EMI), also known as electrical magnetic distortion, is a phenomenon that can significantly impact the performance of wireless communication systems. One of the key metrics affected by EMI is the Received Signal Strength Indicator (RSSI), which measures the power leve...
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Sunrise in Lisbon Harbour, December 2020
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Absorption and Reflection
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Explore the impact of human presence on RSSI and the challenges it introduces, along with effective mitigation strategies in wireless communication systems.
Introduction
Introduction
Introduction
Introduction
Introduction
Basics of the Logrank Test
Basics of the Logrank Test
Basics of the Logrank Test
Basics of the Logrank Test
There is a clear reason why stepwise regression is usually inappropriate, along with several other significant drawbacks. This article will delve into these issues, providing an in-depth understanding of why stepwise selection is generally detrimental to statistical estimates.
Introduction
Introduction
Introduction
Introduction
Introduction
Introduction
1. Introduction
1. Introduction
1. Introduction
1. Introduction
Normal Distribution: Explained
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
In the world of software development, maintaining code quality and consistency is crucial. Git hooks, particularly pre-commit hooks, are a powerful tool that can automate and enforce these standards before code is committed to the repository. This article will guide you through the steps to set u...
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
The Central Limit Theorem (CLT) is one of the cornerstone results in probability theory and statistics. It provides a foundational understanding of how the distribution of sums of random variables behaves. At its core, the CLT asserts that under certain conditions, the sum of a large number of ra...
Statistical estimates always have some uncertainty. Consider a simple example of modeling house prices based solely on their area using linear regression. A prediction from this model wouldn’t reveal the exact value of a house based on its area, because different houses of the same size can have ...
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
An in-depth look at financial models such as Copula and GARCH, their importance in quantitative analysis, and practical applications with Python.
Outlier detection presents significant challenges, particularly in evaluating the effectiveness of outlier detection algorithms. Traditional methods of evaluation, such as those used in predictive modeling, are often inapplicable due to the lack of labeled data. This article introduces a method k...
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
Albert Einstein’s quote, “Everything should be made as simple as possible, but not simpler,” encapsulates a fundamental principle in science and analytics. It emphasizes the importance of simplicity and clarity while cautioning against oversimplification that can lead to loss of essential detail ...
This article rigorously explores the Central Limit Theorem for m-dependent random variables under sub-linear expectations, presenting new inequalities, proof outlines, and implications in modeling dependent sequences.
This article rigorously explores the Central Limit Theorem for m-dependent random variables under sub-linear expectations, presenting new inequalities, proof outlines, and implications in modeling dependent sequences.
This article rigorously explores the Central Limit Theorem for m-dependent random variables under sub-linear expectations, presenting new inequalities, proof outlines, and implications in modeling dependent sequences.
Sequential detection of structural changes in models is a critical aspect in various domains, enabling timely and informed decision-making. This involves identifying moments when the parameters or structure of a model change, often signaling significant events or shifts in the underlying data-gen...
Sequential detection of structural changes in models is a critical aspect in various domains, enabling timely and informed decision-making. This involves identifying moments when the parameters or structure of a model change, often signaling significant events or shifts in the underlying data-gen...
Introducing ikNN: An Interpretable k Nearest Neighbors Model
Introducing ikNN: An Interpretable k Nearest Neighbors Model
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
An exploration of the Solow Growth Model’s extensions, including the effects of technological advancement and human capital on economic growth.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
A guide on developing custom Python libraries to meet specific industry needs, focusing on software development and automation.
Imagine building a model to predict house prices based on features like size, location, and amenities. If you accidentally include the actual selling price during training, the model learns this private information instead of the underlying patterns in the other features. This is data leakage, co...
Imagine building a model to predict house prices based on features like size, location, and amenities. If you accidentally include the actual selling price during training, the model learns this private information instead of the underlying patterns in the other features. This is data leakage, co...
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn the fundamentals of Structural Equation Modeling (SEM) with latent variables. This guide covers measurement models, path analysis, factor loadings, and more for researchers and statisticians.
Learn how to design and implement utility classes in Python. This guide covers best practices, real-world examples, and tips for building reusable, efficient code using object-oriented programming.
Learn how to design and implement utility classes in Python. This guide covers best practices, real-world examples, and tips for building reusable, efficient code using object-oriented programming.
Learn how to design and implement utility classes in Python. This guide covers best practices, real-world examples, and tips for building reusable, efficient code using object-oriented programming.
Learn how to design and implement utility classes in Python. This guide covers best practices, real-world examples, and tips for building reusable, efficient code using object-oriented programming.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
Learn how to use pre-commit tools in Python to enforce code quality and consistency before committing changes. This guide covers the setup, configuration, and best practices for using Git hooks to streamline your workflow.
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Explore how Python and network analysis can be used to implement and optimize circular economy models. Learn how systems thinking and data science tools can drive sustainability and resource efficiency.
Discover the Kruskal-Wallis Test, a powerful non-parametric statistical method used for comparing multiple groups. Learn when and how to apply it in data analysis where assumptions of normality don’t hold.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Learn how to solve the Vehicle Routing Problem (VRP) using Python and optimization algorithms. This guide covers strategies for efficient transportation and logistics solutions.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Explore energy optimization strategies for production facilities to reduce costs and improve efficiency. This model incorporates cogeneration plants, machine flexibility, and operational adjustments for maximum savings.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
Learn how to calculate and interpret the Coefficient of Variation (CV), a crucial statistical measure of relative variability. This guide explores its applications and limitations in various data analysis contexts.
Explore how mathematics shapes modern society across fields like technology, education, and problem-solving. This article delves into the often overlooked impact of mathematics on innovation and societal progress.
Explore how mathematics shapes modern society across fields like technology, education, and problem-solving. This article delves into the often overlooked impact of mathematics on innovation and societal progress.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore the simulation of pedestrian evacuation in environments impacted by smoke. This guide covers key models such as the Social Force Model and Advection-Diffusion Equation to assess evacuation efficiency under smoke propagation conditions.
Explore how graph theory is applied to optimize production systems and supply chains. Learn how network optimization and resource allocation techniques improve efficiency and streamline operations.
Explore how graph theory is applied to optimize production systems and supply chains. Learn how network optimization and resource allocation techniques improve efficiency and streamline operations.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how mathematics influences electronic music creation through sound synthesis, rhythm, and algorithmic composition. Explore the role of numbers in shaping digital signal processing and generative music.
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Discover how data science is transforming the fight against climate change with new methods for understanding and reducing global warming impacts.
Learn why a deep understanding of machine learning fundamentals is more valuable than expertise in specific tools and frameworks.
Learn why a deep understanding of machine learning fundamentals is more valuable than expertise in specific tools and frameworks.
Moving averages are a cornerstone of stock trading, renowned for their ability to illuminate price trends by filtering out short-term volatility. But the utility of moving averages extends far beyond the financial markets. When applied to the analysis of individual behavior, moving averages offer...
Explore the intricacies of outlier detection using distance metrics and metric learning techniques. This article delves into methods such as Random Forests and distance metric learning to improve outlier detection accuracy.
Explore the challenges of using traditional hypothesis testing for detecting data drift in machine learning models and learn how Bayesian probability offers a more robust alternative for monitoring data shifts.
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
Learn how to implement real-time data streaming using Python and Apache Kafka. This guide covers key concepts, setup, and best practices for managing data streams in real-time processing pipelines.
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
Explore the complexity of real-world data distributions beyond the normal distribution. Learn about log-normal distributions, heavy-tailed phenomena, and how the Central Limit Theorem and Extreme Value Theory influence data analysis.
Learn about sequential detection techniques for identifying switches in models with changing structures. Explore methods for detecting structural changes in time-series data and dynamic systems.
Explore how Python and machine learning can be applied to analyze and improve building energy efficiency. Learn key techniques for assessing sustainability, optimizing energy usage, and reducing carbon footprints.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
Explore the full potential of nonparametric tests, going beyond the Mann-Whitney Test. Learn how techniques like quantile regression and other nonparametric methods offer robust alternatives in statistical analysis.
KMeans is widely used, but it’s not always the best clustering algorithm for your data. Explore alternative methods like Gaussian Mixture Models and other clustering techniques to improve your machine learning results.
KMeans is widely used, but it’s not always the best clustering algorithm for your data. Explore alternative methods like Gaussian Mixture Models and other clustering techniques to improve your machine learning results.
KMeans is widely used, but it’s not always the best clustering algorithm for your data. Explore alternative methods like Gaussian Mixture Models and other clustering techniques to improve your machine learning results.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
Learn about the Wilcoxon Signed-Rank Test, a robust non-parametric method for comparing paired samples, especially useful when data is skewed or contains outliers.
An exploration of cross-validation techniques in machine learning, focusing on methods to evaluate and enhance model performance while mitigating overfitting risks.
A detailed guide on the confusion matrix and performance metrics in machine learning. Learn when to use accuracy, precision, recall, F1-score, and how to fine-tune classification thresholds for real-world impact.
A detailed guide on the confusion matrix and performance metrics in machine learning. Learn when to use accuracy, precision, recall, F1-score, and how to fine-tune classification thresholds for real-world impact.
A detailed guide on the confusion matrix and performance metrics in machine learning. Learn when to use accuracy, precision, recall, F1-score, and how to fine-tune classification thresholds for real-world impact.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Importance Sampling offers an efficient alternative to traditional Monte Carlo simulations for portfolio credit risk estimation by focusing on rare, significant loss events.
Multicollinearity is a common issue in regression analysis. Learn about its implications, misconceptions, and techniques to manage it in statistical modeling.
Learn how machine learning optimizes supply chain operations by enhancing demand forecasting, inventory management, logistics, and more, driving efficiency and business value.
Learn how machine learning optimizes supply chain operations by enhancing demand forecasting, inventory management, logistics, and more, driving efficiency and business value.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
This article delves into the role of machine learning in managing forest fires in Portugal, offering a detailed analysis of early detection, risk assessment, and strategic response, with a focus on the challenges posed by eucalyptus forests.
Machine learning is revolutionizing forest fire management through advanced models, real-time data integration, and emerging technologies like IoT and blockchain, offering a holistic and adaptive strategy for combating forest fires.
Discover how machine learning is revolutionizing healthcare analytics, from predictive patient outcomes to personalized medicine, and the challenges faced in integrating ML into healthcare.
Unlock the power of Bayesian statistics in machine learning through probabilistic reasoning, offering insights into model uncertainty, predictive distributions, and real-world applications.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Discover the implications of assigning different job titles in data science teams, examining how uniform or specialized titles affect team unity, role clarity, and individual motivation.
Understand how Markov chains can be used to model customer behavior in cloud services, enabling predictions of usage patterns and helping optimize service offerings.
This article explores the often-overlooked importance of data quality in the data industry and emphasizes the urgent need for defined roles in data design, collection, and quality assurance.
A deep dive into using Genetic Algorithms to create more accurate, interpretable decision trees for classification tasks.
A deep dive into using Genetic Algorithms to create more accurate, interpretable decision trees for classification tasks.
A complete guide to writing the sample size justification section for your clinical trial protocol, covering key statistical concepts like power, error thresholds, and outcome assumptions.
A complete guide to writing the sample size justification section for your clinical trial protocol, covering key statistical concepts like power, error thresholds, and outcome assumptions.
A complete guide to writing the sample size justification section for your clinical trial protocol, covering key statistical concepts like power, error thresholds, and outcome assumptions.
A complete guide to writing the sample size justification section for your clinical trial protocol, covering key statistical concepts like power, error thresholds, and outcome assumptions.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
Discover how simulated annealing, inspired by metallurgy, offers a powerful optimization method for machine learning models, especially when dealing with complex and non-convex loss functions.
Explore the differences between ROC AUC and Precision-Recall AUC in machine learning and learn when to use each metric for classification tasks.
Explore the differences between ROC AUC and Precision-Recall AUC in machine learning and learn when to use each metric for classification tasks.
The fusion of Business Intelligence and Machine Learning offers a pathway from historical analysis to predictive and prescriptive decision-making.
Monotonic constraints are crucial for building reliable and interpretable machine learning models. Discover how they are applied in causal ML and business decisions.
Monotonic constraints are crucial for building reliable and interpretable machine learning models. Discover how they are applied in causal ML and business decisions.
Monotonic constraints are crucial for building reliable and interpretable machine learning models. Discover how they are applied in causal ML and business decisions.
This checklist helps Data Science professionals ensure thorough validation of their projects before declaring success and deploying models.
This checklist helps Data Science professionals ensure thorough validation of their projects before declaring success and deploying models.
Explore how to perform effective Exploratory Data Analysis (EDA) using Pandas, a powerful Python library. Learn data loading, cleaning, visualization, and advanced EDA techniques.
Explore Automated Prompt Engineering (APE), a powerful method to automate and optimize prompts for Large Language Models, enhancing their task performance and efficiency.
Explore Automated Prompt Engineering (APE), a powerful method to automate and optimize prompts for Large Language Models, enhancing their task performance and efficiency.
Explore Automated Prompt Engineering (APE), a powerful method to automate and optimize prompts for Large Language Models, enhancing their task performance and efficiency.
Explore Automated Prompt Engineering (APE), a powerful method to automate and optimize prompts for Large Language Models, enhancing their task performance and efficiency.
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
This article dives into the implementation of continuous machine learning deployment on edge devices, using MLOps and IoT management tools for a real-world agriculture use case.
A data-driven business strategy integrates Business Intelligence and Data Science to drive informed decisions, optimize resources, and stay competitive.
This article explores the fine line between Machine Learning Engineering (MLE) and MLOps roles, delving into their shared responsibilities, unique contributions, and how these roles integrate in small to large teams.
This article explores the fine line between Machine Learning Engineering (MLE) and MLOps roles, delving into their shared responsibilities, unique contributions, and how these roles integrate in small to large teams.
This article explores the fine line between Machine Learning Engineering (MLE) and MLOps roles, delving into their shared responsibilities, unique contributions, and how these roles integrate in small to large teams.
A detailed exploration of the ARIMA model for time series forecasting. Understand its components, parameter identification techniques, and comparison with ARIMAX, SARIMA, and ARMA.
An in-depth review of the role of simple distributional properties, like mean and standard deviation, in time-series classification as a baseline approach.
A comprehensive review of simple distributional properties such as mean and standard deviation as a strong baseline for time-series classification in standardized benchmarks.
A comprehensive review of simple distributional properties such as mean and standard deviation as a strong baseline for time-series classification in standardized benchmarks.
Explore time-series classification in Python with step-by-step examples using simple models, the catch22 feature set, and UEA/UCR repository benchmarking with statistical tests.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
The magnitude of variables in machine learning models can have significant impacts, particularly on linear regression, neural networks, and models using distance metrics. This article explores why feature scaling is crucial and which models are sensitive to variable magnitude.
Data drift can significantly affect the performance of machine learning models over time. Learn about different types of drift and how they impact model predictions in dynamic environments.
Data drift can significantly affect the performance of machine learning models over time. Learn about different types of drift and how they impact model predictions in dynamic environments.
Even the best machine learning models experience performance degradation over time due to model drift. Learn about the causes of model drift and how it affects production systems.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
Data-driven decision-making, powered by data science and machine learning, is becoming central to business strategy. Learn how companies are integrating data science into strategic planning to improve outcomes in customer segmentation, churn prediction, and recommendation systems.
Machine learning is revolutionizing medical diagnosis by providing faster, more accurate tools for detecting diseases such as cancer, heart disease, and neurological disorders.
This article provides an in-depth comparison between the t-test and z-test, highlighting their differences, appropriate usage, and real-world applications, with examples of one-sample, two-sample, and paired t-tests.
This article provides an in-depth comparison between the t-test and z-test, highlighting their differences, appropriate usage, and real-world applications, with examples of one-sample, two-sample, and paired t-tests.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Natural Language Processing (NLP) is revolutionizing healthcare by enabling the extraction of valuable insights from unstructured data. This article explores NLP applications, including extracting patient insights, mining medical literature, and aiding diagnosis.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Wearable devices generate real-time health data that, combined with big data analytics, offer transformative insights for chronic disease monitoring, early diagnosis, and preventive healthcare.
Data science is transforming our approach to antibiotic resistance by identifying patterns in antibiotic use, proposing interventions, and aiding in the fight against superbugs.
Data science is transforming our approach to antibiotic resistance by identifying patterns in antibiotic use, proposing interventions, and aiding in the fight against superbugs.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Mary Jackson was NASA’s first Black female engineer and a trailblazer in aerospace engineering. Her dedication to diversity and inclusion made her an advocate for opportunities for women and minorities in STEM.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
Learn about coverage probability, a crucial concept in statistical estimation and prediction. Understand how confidence intervals are constructed and evaluated through nominal and actual coverage probability.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
This article delves deeply into percentile relativity indices, a novel approach to measuring income inequality, offering fresh insights into income distribution and its societal implications.
Dynamic systems theory helps economists analyze the evolution of economic variables over time, focusing on stability and equilibrium.
Dynamic systems theory helps economists analyze the evolution of economic variables over time, focusing on stability and equilibrium.
Dynamic systems theory helps economists analyze the evolution of economic variables over time, focusing on stability and equilibrium.
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
This article explores the deep connections between correlation, covariance, and standard deviation, three fundamental concepts in statistics and data science that quantify relationships and variability in data.
This in-depth guide explains heteroscedasticity in data analysis, highlighting its implications and techniques to manage non-constant variance.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
This detailed guide covers exponential smoothing methods for time series forecasting, including simple, double, and triple exponential smoothing (ETS). Learn how these methods work, how they compare to ARIMA, and practical applications in retail, finance, and inventory management.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
This article provides an in-depth look at STL and X-13-SEATS, two powerful methods for decomposing time series into trend, seasonal, and residual components. Learn how these methods help model seasonality in time series forecasting.
Mary Somerville’s work in astronomy and mathematical physics earned her recognition as one of the first female scientists, making complex scientific concepts accessible.
Mary Somerville’s work in astronomy and mathematical physics earned her recognition as one of the first female scientists, making complex scientific concepts accessible.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
Emmy Noether’s work in algebra and physics established her as a pioneer, particularly through her groundbreaking theorem linking symmetries to conservation laws.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Capture-Mark-Recapture (CMR) is a powerful statistical method for estimating wildlife populations, relying on six key assumptions for reliability.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
Grubbs’ test is a statistical method used to detect outliers in a univariate dataset, assuming the data follows a normal distribution. This article explores its mechanics, usage, and applications.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
The Liquid State Machine offers a unique framework for computations within biological neural networks and adaptive artificial intelligence. Explore its fundamentals, theoretical background, and practical applications.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
This article critically examines the use of Bayesian posterior distributions as test statistics, highlighting the challenges and implications.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Ensemble methods combine multiple models to improve accuracy, robustness, and generalization. This guide breaks down core techniques like bagging, boosting, and stacking, and explores when and how to use them effectively.
Optimal control theory, employing Hamiltonian and Lagrangian methods, offers powerful tools in modeling and optimizing fiscal and monetary policy.
Optimal control theory, employing Hamiltonian and Lagrangian methods, offers powerful tools in modeling and optimizing fiscal and monetary policy.
Optimal control theory, employing Hamiltonian and Lagrangian methods, offers powerful tools in modeling and optimizing fiscal and monetary policy.
Optimal control theory, employing Hamiltonian and Lagrangian methods, offers powerful tools in modeling and optimizing fiscal and monetary policy.
Optimal control theory, employing Hamiltonian and Lagrangian methods, offers powerful tools in modeling and optimizing fiscal and monetary policy.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The rich are getting richer while the poor remain poor. This article dives into the physics-based models that explain the inherent inequality in wealth distribution.
The integration of IoT and big data is revolutionizing elderly care by enabling remote monitoring systems that track vital signs, detect emergencies, and ensure quick responses to health risks.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Explore how machine learning can be leveraged to forecast commodity prices, such as oil and gold, using advanced predictive models and economic indicators.
Statistical AI leverages probabilistic reasoning and data-driven inference to build adaptive and intelligent systems.
Statistical AI leverages probabilistic reasoning and data-driven inference to build adaptive and intelligent systems.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
State Space Models (SSMs) offer a versatile framework for time series analysis, especially in dynamic systems. This article explores discretization, the Kalman filter, and Bayesian approaches, including their use in econometrics.
Dixon’s Q test is a statistical method used to detect and reject outliers in small datasets, assuming normal distribution. This article explains its mechanics, assumptions, and application.
Peirce’s Criterion is a robust statistical method devised by Benjamin Peirce for detecting and eliminating outliers from data. This article explains how Peirce’s Criterion works, its assumptions, and its application.
Kernel Density Estimation (KDE) is a non-parametric technique offering flexibility in modeling complex data distributions, aiding in visualization, density estimation, and model selection.
Chauvenet’s Criterion is a statistical method used to determine whether a data point is an outlier. This article explains how the criterion works, its assumptions, and its application in real-world data analysis.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Learn how decision-makers in industries like logistics, finance, and manufacturing use linear optimization to allocate scarce resources effectively, maximizing profits and minimizing costs.
Machine learning models are revolutionizing post-hospitalization care by predicting hospital readmissions in elderly patients, helping healthcare providers optimize treatment and reduce complications.
Machine learning models are revolutionizing post-hospitalization care by predicting hospital readmissions in elderly patients, helping healthcare providers optimize treatment and reduce complications.
Multi-agent systems are redefining how financial tasks like M&A analysis can be approached, using teams of collaborative LLMs with distinct responsibilities.
Multi-agent systems are redefining how financial tasks like M&A analysis can be approached, using teams of collaborative LLMs with distinct responsibilities.
Multi-agent systems are redefining how financial tasks like M&A analysis can be approached, using teams of collaborative LLMs with distinct responsibilities.
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
Machine learning is reshaping elderly mental health care. This article explores how data-driven insights help detect depression, track mood changes, and identify early signs of cognitive decline.
Differential equations are essential in modeling economic growth, providing insight into long-term trends and the impact of policy changes on macroeconomic variables.
Differential equations are essential in modeling economic growth, providing insight into long-term trends and the impact of policy changes on macroeconomic variables.
Differential equations are essential in modeling economic growth, providing insight into long-term trends and the impact of policy changes on macroeconomic variables.
Nonlinear growth models offer a richer and more realistic framework for understanding macroeconomic development over time. This article explores the mathematical structures and real-world relevance of non-linear dynamics in economic growth theory.
Nonlinear growth models offer a richer and more realistic framework for understanding macroeconomic development over time. This article explores the mathematical structures and real-world relevance of non-linear dynamics in economic growth theory.
Nonlinear growth models offer a richer and more realistic framework for understanding macroeconomic development over time. This article explores the mathematical structures and real-world relevance of non-linear dynamics in economic growth theory.
Nonlinear growth models offer a richer and more realistic framework for understanding macroeconomic development over time. This article explores the mathematical structures and real-world relevance of non-linear dynamics in economic growth theory.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
This in-depth guide explores Seasonal ARIMA (SARIMA) for forecasting time series with seasonal components. Learn parameter tuning, interpretation, and Python implementation with real-world examples.
Non-stationarity is one of the biggest challenges in time series analysis. Explore proven techniques and statistical tools to transform non-stationary data into model-ready series.
Non-stationarity is one of the biggest challenges in time series analysis. Explore proven techniques and statistical tools to transform non-stationary data into model-ready series.
Non-stationarity is one of the biggest challenges in time series analysis. Explore proven techniques and statistical tools to transform non-stationary data into model-ready series.
Non-stationarity is one of the biggest challenges in time series analysis. Explore proven techniques and statistical tools to transform non-stationary data into model-ready series.
Non-stationarity is one of the biggest challenges in time series analysis. Explore proven techniques and statistical tools to transform non-stationary data into model-ready series.
Model drift is a silent model killer in production machine learning systems. Over time, shifts in data distributions or target concepts can cause even the most sophisticated models to fail. This article explores what model drift is, why it happens, and how to deal with it effectively.
Model drift is a silent model killer in production machine learning systems. Over time, shifts in data distributions or target concepts can cause even the most sophisticated models to fail. This article explores what model drift is, why it happens, and how to deal with it effectively.
Model drift is a silent model killer in production machine learning systems. Over time, shifts in data distributions or target concepts can cause even the most sophisticated models to fail. This article explores what model drift is, why it happens, and how to deal with it effectively.
Model drift is a silent model killer in production machine learning systems. Over time, shifts in data distributions or target concepts can cause even the most sophisticated models to fail. This article explores what model drift is, why it happens, and how to deal with it effectively.
Model drift is a silent model killer in production machine learning systems. Over time, shifts in data distributions or target concepts can cause even the most sophisticated models to fail. This article explores what model drift is, why it happens, and how to deal with it effectively.
Why the intuitive idea of regression confidence bands breaks down under mathematical scrutiny.
Why the intuitive idea of regression confidence bands breaks down under mathematical scrutiny.
Why the intuitive idea of regression confidence bands breaks down under mathematical scrutiny.
Why the intuitive idea of regression confidence bands breaks down under mathematical scrutiny.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
Monte Carlo simulations offer a powerful way to model uncertainty in macroeconomic systems. This article explores how they’re applied to stress testing, forecasting, and policy analysis in complex economic models.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
This case study shows how an LLM-powered agent automates the analysis of earnings call transcripts—summarizing key points, extracting financial guidance, and improving analyst productivity.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Model drift is inevitable in production ML systems. This guide explores monitoring strategies, alert systems, and retraining workflows to keep models accurate and robust over time.
Large Language Model (LLM) agents are revolutionizing the finance industry by automating complex workflows, generating insightful analysis, and improving decision-making. This article explores their architecture, applications, and future potential.
Large Language Model (LLM) agents are revolutionizing the finance industry by automating complex workflows, generating insightful analysis, and improving decision-making. This article explores their architecture, applications, and future potential.
Large Language Model (LLM) agents are revolutionizing the finance industry by automating complex workflows, generating insightful analysis, and improving decision-making. This article explores their architecture, applications, and future potential.
Large Language Model (LLM) agents are revolutionizing the finance industry by automating complex workflows, generating insightful analysis, and improving decision-making. This article explores their architecture, applications, and future potential.
Large Language Model (LLM) agents are revolutionizing the finance industry by automating complex workflows, generating insightful analysis, and improving decision-making. This article explores their architecture, applications, and future potential.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Agent-Based Models (ABM) offer a powerful framework for simulating macroeconomic systems by modeling interactions between heterogeneous agents. This article delves into the theory, structure, and use of ABMs in economic research.
Statistical models lie at the heart of modern data science and quantitative research, enabling analysts to infer, predict, and simulate outcomes from structured data.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Natural Language Processing offers powerful tools for interpreting economic intent behind political speeches and policy documents. This article explores NLP techniques used in economic policy forecasting and analysis.
Least Angle Regression, or LARS, is an efficient regression algorithm designed for high-dimensional data. It provides a pathwise approach to linear regression that is especially useful in the presence of multicollinearity or when feature selection is crucial.
Hyperparameter tuning can drastically improve model performance. Explore common search strategies and tools.
Deploying machine learning models to production requires planning and robust infrastructure. Here are key practices to ensure success.
Ethical considerations are critical when deploying machine learning systems that affect real people.
Ethical considerations are critical when deploying machine learning systems that affect real people.
SMOTE generates synthetic samples to rebalance datasets, but using it blindly can create unrealistic data and biased models.
SMOTE generates synthetic samples to rebalance datasets, but using it blindly can create unrealistic data and biased models.
Discover how AI-powered tools are reshaping mental health care for older adults, offering early detection, personalized mood tracking, cognitive monitoring, and integrated clinical support.
Discover how AI-powered tools are reshaping mental health care for older adults, offering early detection, personalized mood tracking, cognitive monitoring, and integrated clinical support.
Discover how AI-powered tools are reshaping mental health care for older adults, offering early detection, personalized mood tracking, cognitive monitoring, and integrated clinical support.
Discover how AI-powered tools are reshaping mental health care for older adults, offering early detection, personalized mood tracking, cognitive monitoring, and integrated clinical support.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Reinforcement Learning (RL) brings intelligent autonomy to industrial maintenance, enabling dynamic optimization through trial-and-error interaction with complex systems.
Survival analysis offers a powerful framework for analyzing time-to-event data in public policy, enabling data-driven decision making across health, welfare, housing, and more.
Survival analysis offers a powerful framework for analyzing time-to-event data in public policy, enabling data-driven decision making across health, welfare, housing, and more.
Survival analysis offers a powerful framework for analyzing time-to-event data in public policy, enabling data-driven decision making across health, welfare, housing, and more.
Survival analysis offers a powerful framework for analyzing time-to-event data in public policy, enabling data-driven decision making across health, welfare, housing, and more.
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
A practical guide to VAR and VECM for multivariate time series forecasting, including math, assumptions, cointegration testing, and Python code.
Survival analysis offers financial institutions a powerful framework for modeling time-to-event data such as default, prepayment, and churn. This guide explores the methodology, financial applications, advanced techniques, and real-world case studies.
Survival analysis offers financial institutions a powerful framework for modeling time-to-event data such as default, prepayment, and churn. This guide explores the methodology, financial applications, advanced techniques, and real-world case studies.
Survival analysis offers financial institutions a powerful framework for modeling time-to-event data such as default, prepayment, and churn. This guide explores the methodology, financial applications, advanced techniques, and real-world case studies.
Survival analysis offers financial institutions a powerful framework for modeling time-to-event data such as default, prepayment, and churn. This guide explores the methodology, financial applications, advanced techniques, and real-world case studies.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
A deep dive into real-time traffic anomaly detection for intelligent transportation systems, covering statistical and machine learning methods for early incident response.
Survival analysis offers a powerful framework to model time-to-event phenomena across the supply chain. This guide explores how to apply it to inventory, perishables, shipment, equipment reliability, and supplier management.
Survival analysis offers a powerful framework to model time-to-event phenomena across the supply chain. This guide explores how to apply it to inventory, perishables, shipment, equipment reliability, and supplier management.
Survival analysis offers a powerful framework to model time-to-event phenomena across the supply chain. This guide explores how to apply it to inventory, perishables, shipment, equipment reliability, and supplier management.
Survival analysis offers a powerful framework to model time-to-event phenomena across the supply chain. This guide explores how to apply it to inventory, perishables, shipment, equipment reliability, and supplier management.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Effective model evaluation is essential for reliable time series forecasting. Learn the most important metrics, validation methods, and strategies for interpreting and improving forecasts.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Learn how to optimize Apache Airflow for production-scale data pipelines, featuring DAG design patterns, executor architecture, error handling frameworks, and monitoring integrations.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Explore the smarter way of splitting nodes in regression trees using Friedman MSE, a computationally efficient and numerically stable alternative to classic variance-based MSE.
Learn how to preregister your SEM study by systematically locking down modeling and analytic decisions to improve scientific transparency and reduce bias.
Learn how to preregister your SEM study by systematically locking down modeling and analytic decisions to improve scientific transparency and reduce bias.
Learn how to preregister your SEM study by systematically locking down modeling and analytic decisions to improve scientific transparency and reduce bias.
Learn how to preregister your SEM study by systematically locking down modeling and analytic decisions to improve scientific transparency and reduce bias.
Learn how data drift and concept drift can degrade machine learning models over time, and why continuous monitoring and adaptive systems are essential for model performance.
Learn how data drift and concept drift can degrade machine learning models over time, and why continuous monitoring and adaptive systems are essential for model performance.
Learn how data drift and concept drift can degrade machine learning models over time, and why continuous monitoring and adaptive systems are essential for model performance.
Learn how data drift and concept drift can degrade machine learning models over time, and why continuous monitoring and adaptive systems are essential for model performance.
Learn how data drift and concept drift can degrade machine learning models over time, and why continuous monitoring and adaptive systems are essential for model performance.
AI and machine learning are transforming renewable energy systems, making them more efficient, reliable, and sustainable. Learn how intelligent technologies are powering the clean energy transition.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
A deep dive into the integration of Natural Language Processing techniques with predictive maintenance to unlock hidden knowledge from unstructured maintenance text.
A data-driven investigation into predictive maintenance’s operational value across industries, exploring statistical models, machine learning architectures, and real-world results.
A data-driven investigation into predictive maintenance’s operational value across industries, exploring statistical models, machine learning architectures, and real-world results.
A data-driven investigation into predictive maintenance’s operational value across industries, exploring statistical models, machine learning architectures, and real-world results.
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
A comprehensive guide to traffic prediction in smart transportation systems, covering data sources, preprocessing, modeling approaches, and real-world Python examples.
Fundamental research is often targeted for cuts due to its lack of immediate outcomes. But eliminating it risks innovation, education, crisis response, and global competitiveness.
Fundamental research is often targeted for cuts due to its lack of immediate outcomes. But eliminating it risks innovation, education, crisis response, and global competitiveness.
Fundamental research is often targeted for cuts due to its lack of immediate outcomes. But eliminating it risks innovation, education, crisis response, and global competitiveness.
Explore the evolution of probability calibration methods in machine learning, from histogram binning to Venn–ABERS predictors, with a deep dive into theory, implementation, and applications.
Explore the evolution of probability calibration methods in machine learning, from histogram binning to Venn–ABERS predictors, with a deep dive into theory, implementation, and applications.
Explore the evolution of probability calibration methods in machine learning, from histogram binning to Venn–ABERS predictors, with a deep dive into theory, implementation, and applications.
Explore the evolution of probability calibration methods in machine learning, from histogram binning to Venn–ABERS predictors, with a deep dive into theory, implementation, and applications.
This review explores the transformative applications of mathematical optimization and machine learning in industrial management, with a focus on production planning, predictive maintenance, and supply chain optimization.
This review explores the transformative applications of mathematical optimization and machine learning in industrial management, with a focus on production planning, predictive maintenance, and supply chain optimization.
This review explores the transformative applications of mathematical optimization and machine learning in industrial management, with a focus on production planning, predictive maintenance, and supply chain optimization.
Short-term thinking and utilitarian pressures are undermining the very institutions that sustain human progress. This is a crisis not just in science policy, but in civilization itself.
Short-term thinking and utilitarian pressures are undermining the very institutions that sustain human progress. This is a crisis not just in science policy, but in civilization itself.
Short-term thinking and utilitarian pressures are undermining the very institutions that sustain human progress. This is a crisis not just in science policy, but in civilization itself.
Short-term thinking and utilitarian pressures are undermining the very institutions that sustain human progress. This is a crisis not just in science policy, but in civilization itself.
Short-term thinking and utilitarian pressures are undermining the very institutions that sustain human progress. This is a crisis not just in science policy, but in civilization itself.
As institutions prioritize immediate applications, pure mathematics faces an existential threat. This article defends abstract research as essential to innovation and long-term progress.
As institutions prioritize immediate applications, pure mathematics faces an existential threat. This article defends abstract research as essential to innovation and long-term progress.
As institutions prioritize immediate applications, pure mathematics faces an existential threat. This article defends abstract research as essential to innovation and long-term progress.
As institutions prioritize immediate applications, pure mathematics faces an existential threat. This article defends abstract research as essential to innovation and long-term progress.
As institutions prioritize immediate applications, pure mathematics faces an existential threat. This article defends abstract research as essential to innovation and long-term progress.






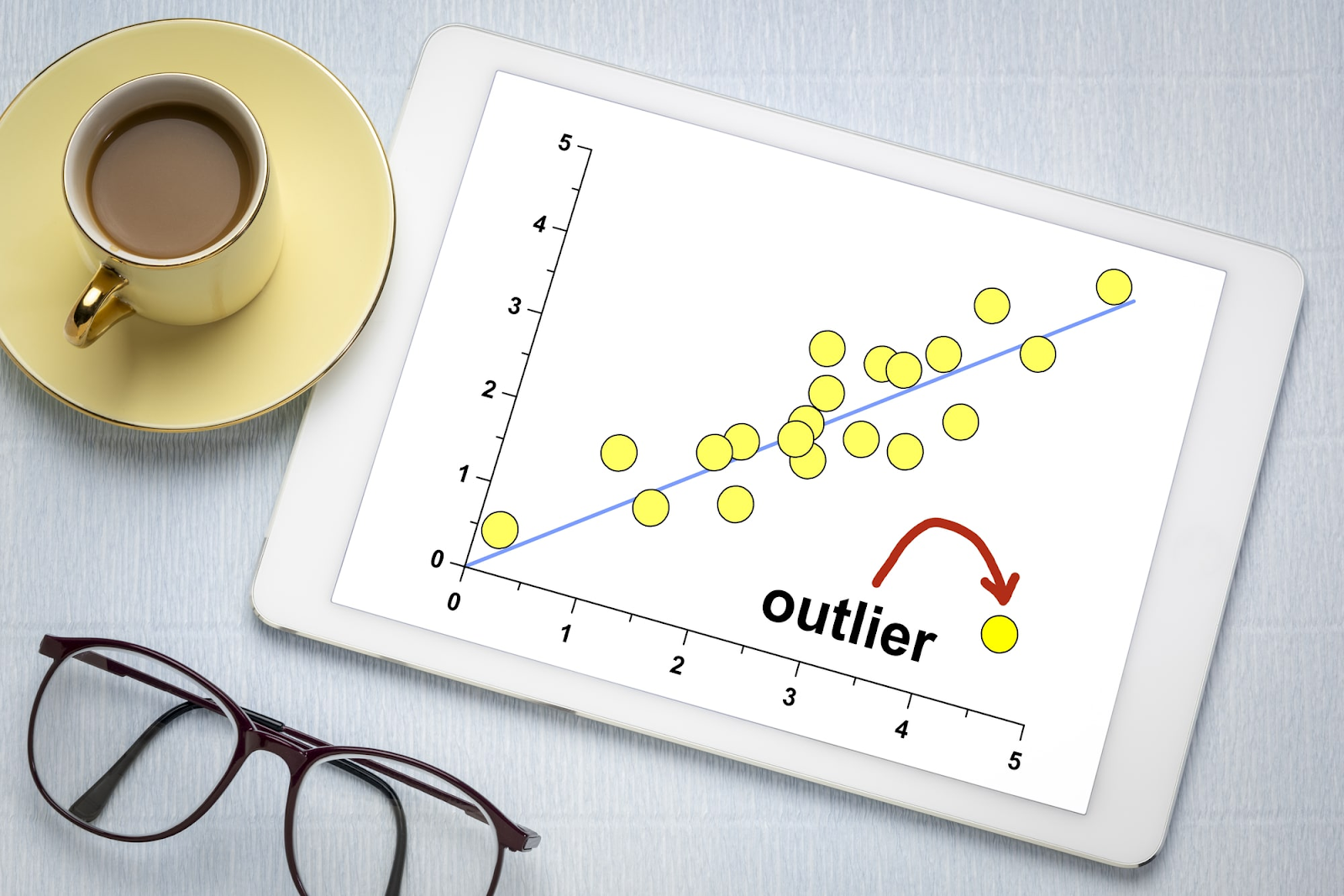


















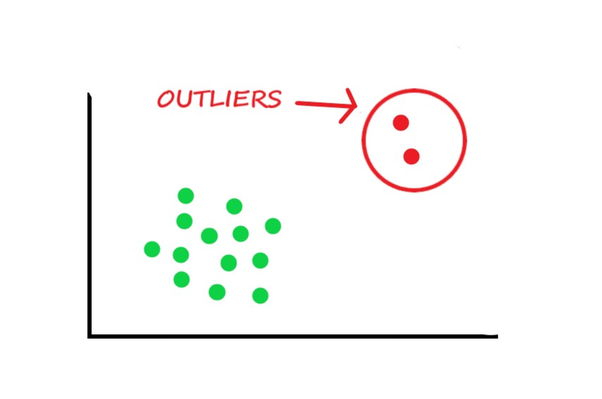
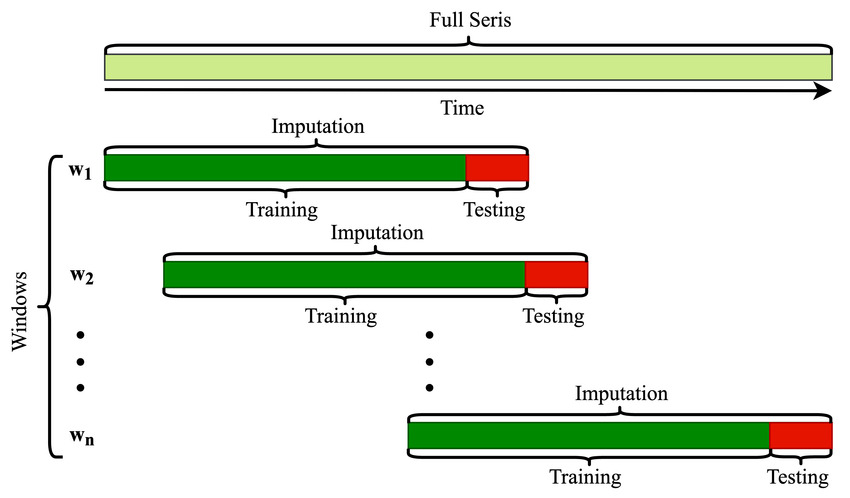


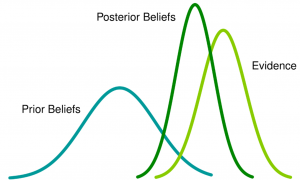





Social network analysis
Critical Review of ‘Bursting the (Filter) Bubble: Interactions of Members of Parliament on Twitter’
Introduction