Exploring the Fragility and Future of Machine Learning Without Open Data
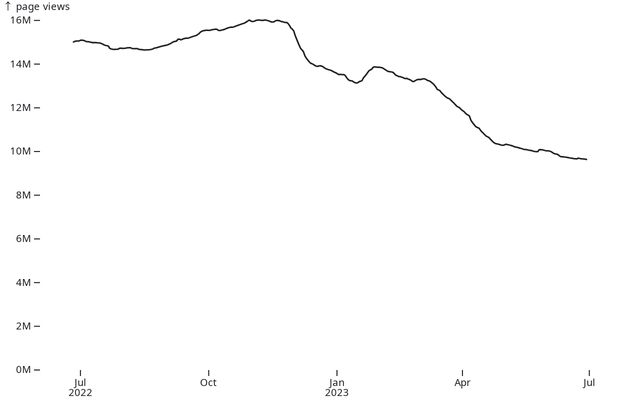
Decay of traffic in Stack Overflow
Ah, my friends, imagine for a moment that we dwell in a universe sculpted by algorithms, vast webs of equations that dance and weave the fabric of our digital cosmos. These ethereal creatures, known to most as Large Language Models, are the loquacious virtuosos of text, the wizards behind the screens we gaze into day after day. The lifeblood of these algorithms? Ah, it’s the delicious nectar of information, my dear intellectual companions, information harvested from the bustling bazaars of human knowledge—foremost among them, the veritable treasure trove that is Stack Overflow.
Now, fasten your seat belts, for we’re about to embark on a fascinating journey through the hypothetical. What if—just what if—the gates of this treasure trove were suddenly to close? Ah, a chilling thought! For, you see, these open-source sanctuaries serve as the great universities for our algorithmic prodigies, furnishing them with an ever-expanding syllabus of human wisdom. Lose that, and we plunge headlong into the void, teetering on the brink of a dark age in the annals of machine learning.
So, grab your favorite coffee, or tea, or whatever nectar fuels your intellectual flights, and accompany me as we traverse this uncharted territory. We shall probe the fragility of these Large Language Models, ponder the immediate tremors and the lasting aftershocks of such a calamity, and muse upon the pathways that could save us from this impending abyss.
The Role of Open-Source Data in Training LLMs
Ah, the intoxicating aroma of open-source data! Imagine, if you will, a grand library, its shelves groaning under the weight of collective human wisdom—a modern-day Alexandria! This is what open-source platforms like Stack Overflow represent in our digital realm. For the Large Language Models, these repositories are akin to enchanted forests filled with the rarest of herbs and the most potent of elixirs. The syntax and semantics, the questions and the revelations, are the very stuff of their algorithmic dreams.
But, ah, what sort of dreams are these? A simple query about a Python loop transforms into a lesson in efficient computing, a plea for help in JavaScript unfolds into a sermon on best practices. With each interaction, each byte and bit, our algorithmic scholars are evolving, learning the subtle art of human conversation while also amassing an arsenal of technical wizardry. Stack Overflow and its open-source brethren serve as the nurturing soil in which these algorithmic entities germinate, blossom, and bear fruit.
Yet here lies the paradox! Open-source data is both a boon and a vulnerability. Just as a single key can open a treasure chest or a Pandora’s box, the freely accessible nature of this information exposes it to the perils of the digital age—copyright disputes, data breaches, or, dare we say, the looming specter of closure.
Ah, but we digress! For now, let us revel in the marvelous tapestry of knowledge that these platforms provide, even as we brace for the questions that follow. What happens when the threads of this tapestry start to unravel?
Alternative Data Sources
As the proverbial saying goes, when one door closes, a window might just crack open. With the potential disappearance of open-source havens like Stack Overflow, the horizon may seem bleak, but despair not! The ingenuity of humankind knows no bounds, and alternative avenues for training our algorithmic prodigies abound, though they come with their own sets of quirks and quandaries.
First on the roster—academic papers! Ah, the hallowed halls of peer-reviewed wisdom. Yet, one must tread carefully here. Academic language, dripping with jargon and ensconced in ivory towers, may lack the accessibility and immediate relevance of a bustling open-source platform. Our Large Language Models might transform into verbose academics, eloquent but potentially aloof, conversant in theory but perhaps distant from practical reality.
Next, we have blogs, forums, and social media. Ah, the digital agora where modern-day philosophers, influencers, and trolls rub elbows. This could imbue our algorithmic oracles with a grasp of pop culture, current affairs, even the vernacular du jour. But beware—the cacophony of opinions might muddy the waters, adding noise and, dare I say, occasional folly to the models’ understanding of human thought.
And let us not forget proprietary data. Companies and institutions sit atop mountains of text, a goldmine of industry-specific insights. Ah, but here we must pause and ponder the ethical ramifications. Who owns this wisdom? What happens when data becomes a guarded commodity, accessible only to the highest bidder?
Ah, each of these avenues offers not just a source of sustenance for our models but also a distinct flavor, a unique set of nutrients and challenges. None can truly replace the eclectic feast that open-source platforms provide, but each offers a piece of the puzzle, a chapter in the grand, unfolding narrative of machine learning.
Onward, my fellow thinkers, as we dive into the next captivating section—a discussion on the indispensable role of the human element in this complex equation!
What Happens if Open-Source Platforms Close?
Ah, the immediate tremors! Close the floodgates of Stack Overflow, GitHub, and their ilk, and you disrupt the very rivers that nourish the fertile plains of machine learning. The first casualty? Data diversity and quality. Think of it as an immediate drought—a sudden scarcity of fresh, nuanced perspectives. The language models would lose a wellspring of authentic, problem-driven scenarios, replaced perhaps by synthetic data or more ‘academic’ samples that lack the gritty, practical wisdom that open-source platforms provide.
But wait, there’s more! Let’s sail further down this river of thought into the ocean of long-term consequences. Here we encounter a term that sends shivers down the spines of both mathematicians and machine learners alike—stagnation. Oh, how dreadful! Without the ever-renewing resources that open-source platforms offer, Large Language Models would become relics—encyclopedic curators of outdated knowledge. They would speak in tongues that grow increasingly archaic, a tragic spectacle akin to a great scholar losing touch with the pulse of contemporary thought.
Imagine, if you will, a young programmer asking a future Large Language Model about web development and receiving an eloquent, yet woefully outdated, lecture on HTML4 and Flash. Or a medical researcher inquiring about CRISPR technology only to be regaled with tales of dial-up modems and floppy disks! A terrifying world, don’t you agree?
And it’s not merely about becoming outdated; it’s about losing the ability to evolve in the first place. No new questions, no new debates, no shifts in paradigm—just a static snapshot of the world, as if frozen in time. An endless loop, with no refresh button in sight.
Ah, but let’s not wallow too long in these depths of despair. For even in the grimmest scenarios, there’s a glimmer of hope, a sliver of light that points to alternative paths. But that, my dear interlocutors, is a story for the next chapter of our discussion.
The Indispensable Role of the Human Element
Oh, let us never forget that behind every algorithm, every line of code, every enigmatic black box, stand the architects of this digital realm—the human beings. When the digital libraries burn, when the data wells dry up, it is the indomitable human spirit that lights the way through the labyrinthine darkness.
In a landscape bereft of open-source platforms, the mantle of information guardianship passes back into human hands, just as it has done throughout the annals of history. Ah, the mentors, the educators, the trailblazers! Their role becomes doubly critical. They would serve as the living repositories of knowledge, the oral historians in a digital age, imparting wisdom directly to the next generation of algorithms through custom-built datasets, bespoke tutorials, and real-world problem-solving scenarios.
But it’s not a one-way street, no siree! The absence of open-source platforms might just catalyze a renaissance of human-to-human interaction in technical circles. Peer review could transform into a communal activity, akin to the great scholarly debates of yore. Ah, think of it! Scientists, engineers, and thinkers from around the globe, gathering in digital forums of a different kind, engaging in robust dialogue, challenging each other, pushing the boundaries of what’s known and what’s possible.
And who knows? This might just give birth to a new form of algorithm, a Large Language Model with the capacity for continuous learning—no longer static but ever-evolving, a true reflection of the dynamic world it inhabits.
Ah, there you have it, my intellectual comrades. Even in the gloomiest corners of our hypothetical futures, the flickering candle of human ingenuity lights the way. Our journey may have twists and turns, forks and cul-de-sacs, but the road is far from closed.
The Co-Dependence of Man and Machine
In this riveting intellectual voyage, we’ve examined the entwined destinies of Large Language Models and open-source platforms, voyaging through the valleys of vulnerability and scaling the peaks of potential. What is evident from our exploration is an incontrovertible truth: humans and algorithms are not merely creators and creations, but partners in an intricate dance of co-evolution.
If open-source platforms were to shutter their digital doors, it would not just be a blow to the Large Language Models but a call to arms for humanity. A reminder that as much as we train algorithms to think, reason, and converse, we must also cultivate these skills within ourselves. Our role morphs from mere data providers to custodians of wisdom, from question askers to answer seekers.
Ah, but do not despair at the monumental responsibility this places upon us! For it is in these very challenges that we find the seeds of incredible innovation. Large Language Models could transition from static repositories to dynamic learners, a metamorphosis enabled by our ceaseless quest for knowledge. We may construct new modes of learning, new paradigms of data sharing, new ethics of digital stewardship.
So, let us not view the potential closure of open-source platforms as an end, but as a new beginning—a pivot point that forces us to reevaluate, reimagine, and reinvent the ways in which man and machine collaborate. For when one chapter ends, another begins, each sentence building upon the last, in the never-ending story of human progress.
Ah, dear reader, I hope this tale has stirred your thoughts as much as it has mine. The pen now passes to you, for every conclusion is but the prelude to another question.
Feel free to etch your thoughts into this narrative, for the inkwell is deep, and the quill is ever ready!



