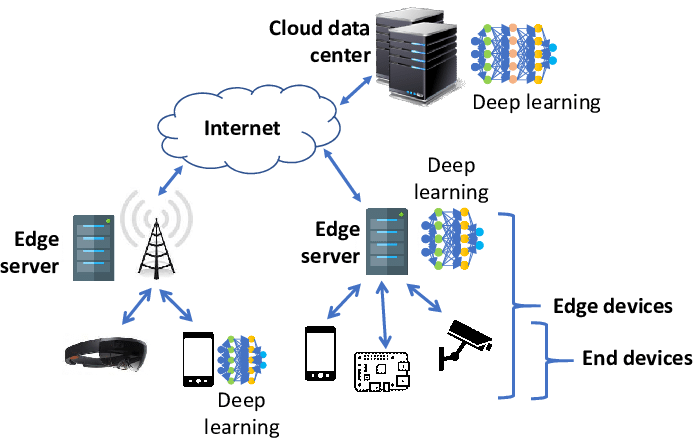
Running machine learning (ML) inference on edge devices—closer to where the data is generated—provides numerous advantages compared to centralized cloud-based inference. These benefits include real-time processing, reduced latency, enhanced privacy, lower operational costs, and the ability to function in environments with intermittent or no internet connectivity. However, setting up an end-to-end ML system for continuous deployment on edge devices presents unique challenges. The process can be significantly more complex than deploying ML models in a centralized cloud environment, primarily due to the distributed nature of edge devices and the need for real-time updates.
The goal of any production-level ML system, especially in edge computing, is to establish a continuous lifecycle where models are trained, deployed, and improved over time. Achieving this requires robust pipelines for model iteration, deployment, and data collection. This article provides an original use case of a smart agriculture system that utilizes continuous ML deployment on edge devices, leveraging MLOps and IoT management platforms.
Real Use Case: Smart Agriculture Monitoring System
In this example, we developed an ML-powered system designed to monitor crop health in remote agricultural fields. The system uses edge devices equipped with cameras and environmental sensors to detect early signs of plant disease and optimize irrigation based on real-time soil conditions. The use of edge devices is crucial in agriculture, where fields are often located in areas with limited internet access, and timely responses to crop health issues are critical.
Problem Statement
Early detection of plant disease and water stress is essential to maintaining healthy crops and ensuring optimal yield. Traditional monitoring methods involve manual inspections, which are time-consuming and prone to human error. By deploying edge devices that can autonomously monitor crop health, we can automate the detection process, reduce response times, and optimize resource usage such as water and fertilizer.
In this use case, edge devices equipped with cameras capture images of crops, while sensors collect environmental data such as temperature, humidity, and soil moisture levels. An object detection model running on the edge devices identifies signs of disease or stress in the plants. The edge inference capabilities allow the system to provide real-time feedback without the need for constant internet connectivity.
Solution Overview: Continuous Machine Learning Pipeline for Edge Devices
The solution comprises two main components:
- MLOps Platform for Training and Retraining the Model: The model training and retraining pipeline is managed through an MLOps platform, which automates the entire process from data preprocessing to model deployment.
- IoT Management Platform for Model Deployment: An IoT management platform is used to deploy the trained models to edge devices in the field, ensuring consistent updates across the fleet.
Training and Deployment Pipeline
1. Training the Model
The model used in this system is a deep learning-based object detection model trained to identify various crop diseases from images. The training pipeline involves the following key steps:
- Data Preprocessing: Images of crops are preprocessed, including tasks such as resizing, augmentation, and normalization, to ensure the data is consistent for model training.
- Model Training: A convolutional neural network (CNN) is trained on a dataset of labeled crop images, with each image annotated to identify healthy crops, diseased plants, and water-stressed areas.
- Model Evaluation: The trained model is evaluated on a validation set to ensure accuracy and robustness before deployment.
Once the model has been successfully trained, it is prepared for deployment to the edge devices. The training pipeline is managed through an MLOps platform, such as Valohai or MLflow, to ensure reproducibility and scalability. The configuration for the pipeline is defined in a YAML file (pipeline.yaml), which includes the steps for data preprocessing, model training, and deployment.
- step:
name: preprocess-data
image: python:3.9
command:
- python preprocess.py --input /data/crops --output /data/processed
- step:
name: train-model
image: pytorch/pytorch:latest
command:
- python train.py --data /data/processed --output /models/crop-disease-detector
- step:
name: deploy-model
image: python:3.9
command:
- zip -r /tmp/model.zip /models/crop-disease-detector
- curl -H "X-API-KEY:$API_KEY" -T /tmp/model.zip "$MODEL_REPOSITORY/model.zip"
environment-variables:
- name: API_KEY
optional: false
- name: MODEL_REPOSITORY
optional: false
In this pipeline, the deploy-model step packages the trained model into a zip file and uploads it to a model repository, such as JFrog Artifactory or a custom storage solution.
2. Model Deployment Using IoT Platform
Once the model has been uploaded to the repository, the next step is deploying it to the edge devices. We use an IoT management platform, such as AWS IoT Greengrass or JFrog Connect, to automate this process. The deployment process involves the following:
Model Distribution
The platform distributes the updated model to all registered edge devices. The devices download the model from the repository and store it locally.
Model Installation
Each device installs the new model and prepares to run inference using the updated version.
Rollback Mechanism
If the deployment process fails on any device, the system automatically rolls back to the previous stable version of the model to prevent system downtime.
This deployment process is designed to be resilient and can be monitored through the IoT management platform, ensuring that each device is running the latest model version without manual intervention.
Continuous Improvement: Retraining and Data Collection
To maintain high accuracy and adaptability, the model must be continuously retrained with new data collected from the edge devices. The retraining pipeline works as follows:
Data Collection
Edge devices collect images of crops along with environmental data throughout the day. This data is uploaded to a central server for processing.
Data Labeling
The collected data is manually or semi-automatically labeled, identifying instances of disease, water stress, or healthy crops.
Model Retraining
The labeled data is used to retrain the model periodically. The retraining process takes into account new disease variants or environmental conditions that the initial model may not have encountered.
The updated model is then deployed back to the edge devices, completing the continuous improvement loop.
Efficiency Considerations
Edge devices have limited computational resources and storage capacity, which must be taken into account when deploying models. To ensure efficient operation, the system incorporates the following strategies:
Model Compression
Techniques such as quantization and pruning are applied to reduce the model size without significant loss in accuracy. This enables the model to run efficiently on devices with constrained hardware.
Data Filtering
Not all data collected by the devices is useful for retraining. The system applies a filtering mechanism that prioritizes edge cases—instances where the model’s confidence is low or where the predictions differ from previous outputs.
By focusing on the most critical data, we reduce the amount of data that needs to be manually labeled and stored, making the continuous training process more manageable.
Conclusion
This smart agriculture monitoring system demonstrates how continuous machine learning deployment on edge devices can be implemented to improve real-time decision-making in environments with limited connectivity. The combination of MLOps and IoT management platforms facilitates the seamless training, deployment, and monitoring of models across a distributed fleet of edge devices.
The benefits of edge inference—such as real-time processing, lower latency, and increased privacy—make it an ideal solution for applications in agriculture, where timely and localized decision-making is essential. By implementing a continuous improvement loop, this system ensures that the model evolves as new data is collected, allowing for more accurate and adaptive predictions over time.
Through careful design and automation, the challenges associated with edge deployment can be mitigated, providing scalable and efficient solutions for a wide range of industries.



